

Model-based Approach to Detecting Densely Overlapping Communities in Networks
AGMfit detects overlapping communities (dense groups of nodes) in networks. AGMfit provides a fast and efficient algorithm to find communities by fitting the Affilated Graph Model to a large network. A community is a set of nodes that are densely connected each other. In many real-world networks, communities tend to overlap as nodes can belong to many communities or groups.
Below, you can find some extra information:
About AGM
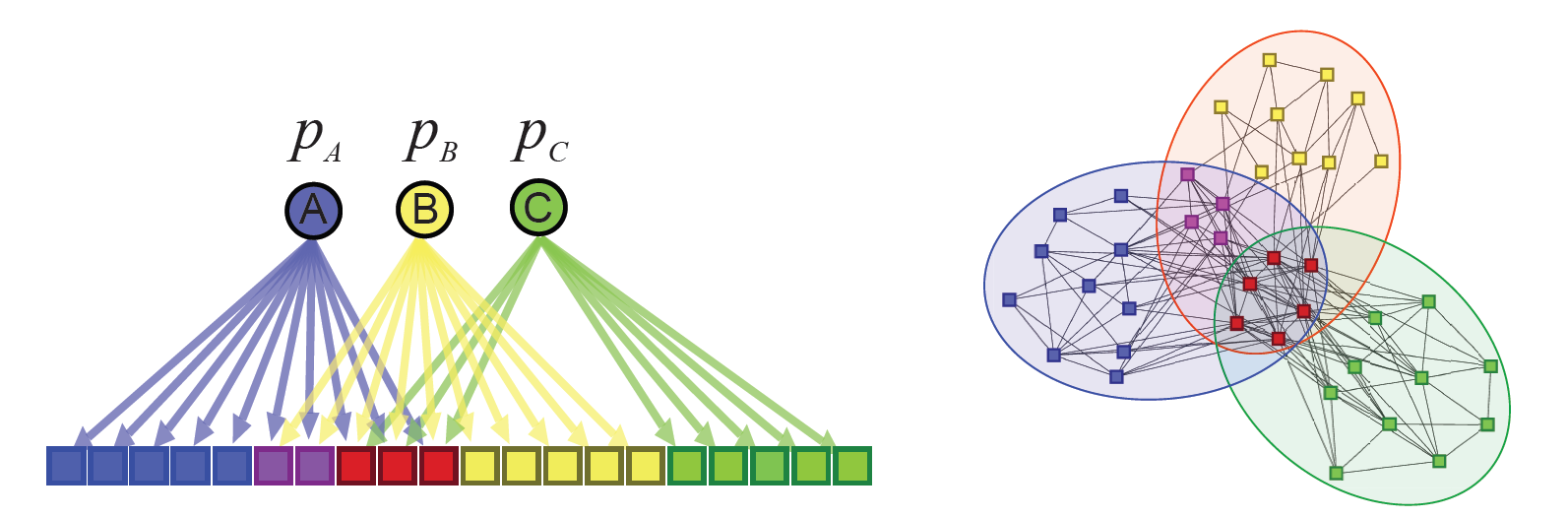
The Affiliation Graph Model (AGM) is a generative model that produces a network from community affilation. The figure below describes an example of bipartite community affiliation graph and a network (Figure 1).
- Figure 1. Left: Bipartite community affilation graph (Circle nodes denote three communities and square nodes represent the nodes of the network), Right: Network generated by AGM with the community affiliation graph on the left
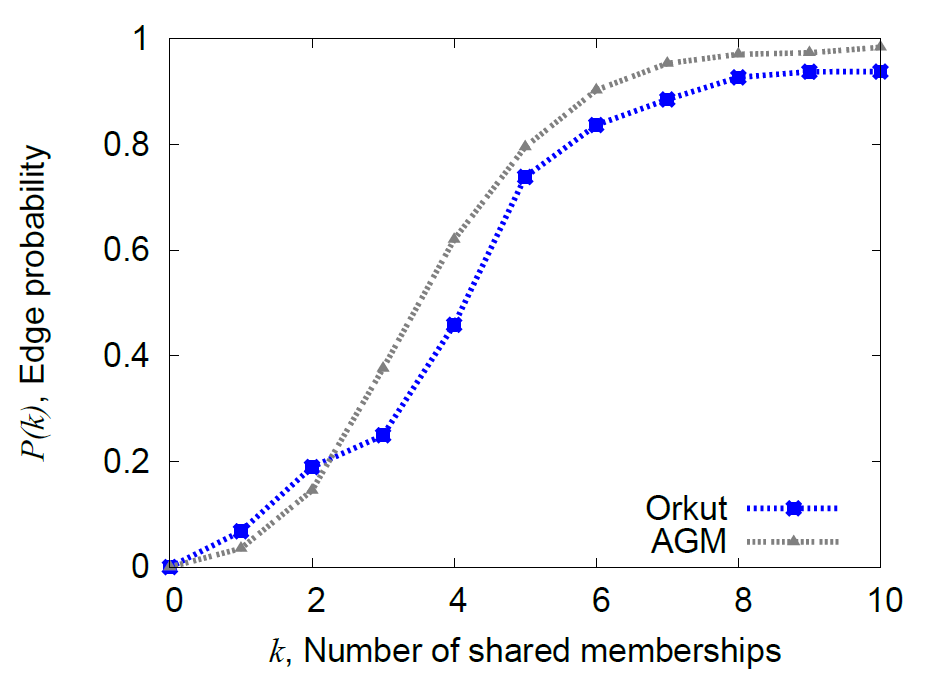
AGM can generate realistic looking graphs. When we synthesize a network using AGM that is fit to a real-world network, the synthetic network exhibits very similar characteristics to those of the real network (Figure 2).
- Figure 2. Edge probability as a function of the number of common community memberships in the Orkut network and as modeled by the AGM, which reliably captures the dependence.
Community detection by AGM
AGMfit is a fast and scalable algorithm to detect overlapping communities from a given graph by fitting the AGM to the graph. When a network is given, AGM can measure the likelihood of a community affiliation graph, and we can find the most likely community affiliation by fitting the AGM to the given network.
If a user specifies the number of communities that the user want to detect, AGMfit finds the corresponding number of communities. If a user does not know how many communities would exist, which is more realistic, AGMfit automatically estimates the number of communities in the graph. User also can control the probability of edges between the nodes that do not share any communities. If a user does not assume a certain probability, AGMfit uses (1 / N^2) where N is the number of nodes in the graph.
For more detail, refer to the following papers:Papers (citation)
Overlapping Communities Explain Core-Periphery Organization of Networks by J. Yang and J. Leskovec, Proceedings of IEEE, 2014.
Community-Affiliation Graph Model for Overlapping Community Detection by J. Yang and J. Leskovec, IEEE International Conference on Data Mining (ICDM), 2012.
Overlapping Community Detection at Scale: A Nonnegative Matrix Factorization Approach by J. Yang and J. Leskovec, ACM International Conference on Web Search and Data Mining (WSDM), 2013.
Community Detection in Networks with Node Attributes by J. Yang, J. McAuley and J. Leskovec, IEEE International Conference on Data Mining (ICDM), 2013.
Detecting Cohesive and 2-mode Communities in Directed and Undirected Networks by J. Yang, J. McAuley and J. Leskovec, ACM International Conference on Web Search and Data Mining (WSDM), 2014.
Examples
We show several examples of communities detected by AGM and underlying networks.
You can click over the graphs to see them bigger!
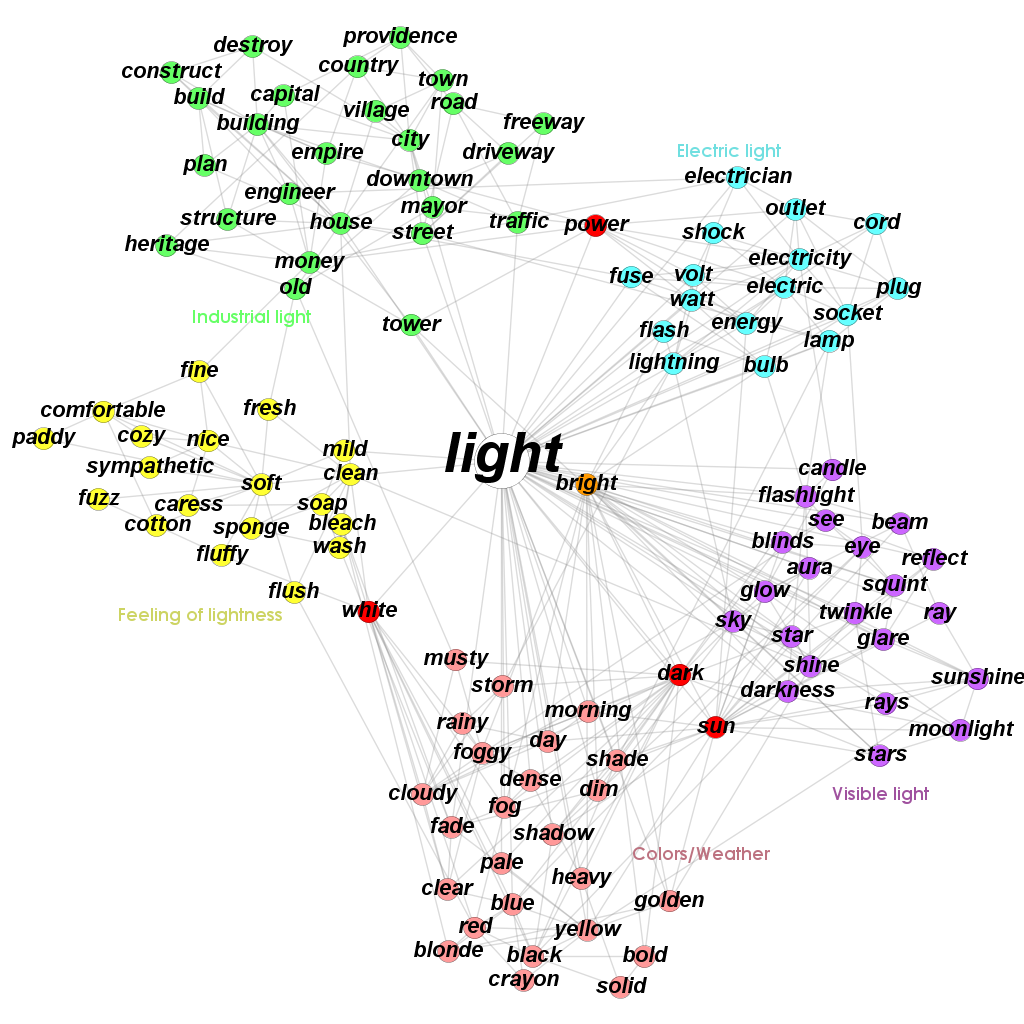
- Communities of the words that "light" belongs to in the University of South Florida Word Association network. AGM detects 5 communities each of which represents distinct aspect of human perceiving light. Red nodes belong to 2 adjacent communities. The orange node (bright) belongs to the 3 communities (Colors/Weather, Visible light, Electric light). The white node (light) belongs to all the communities. :
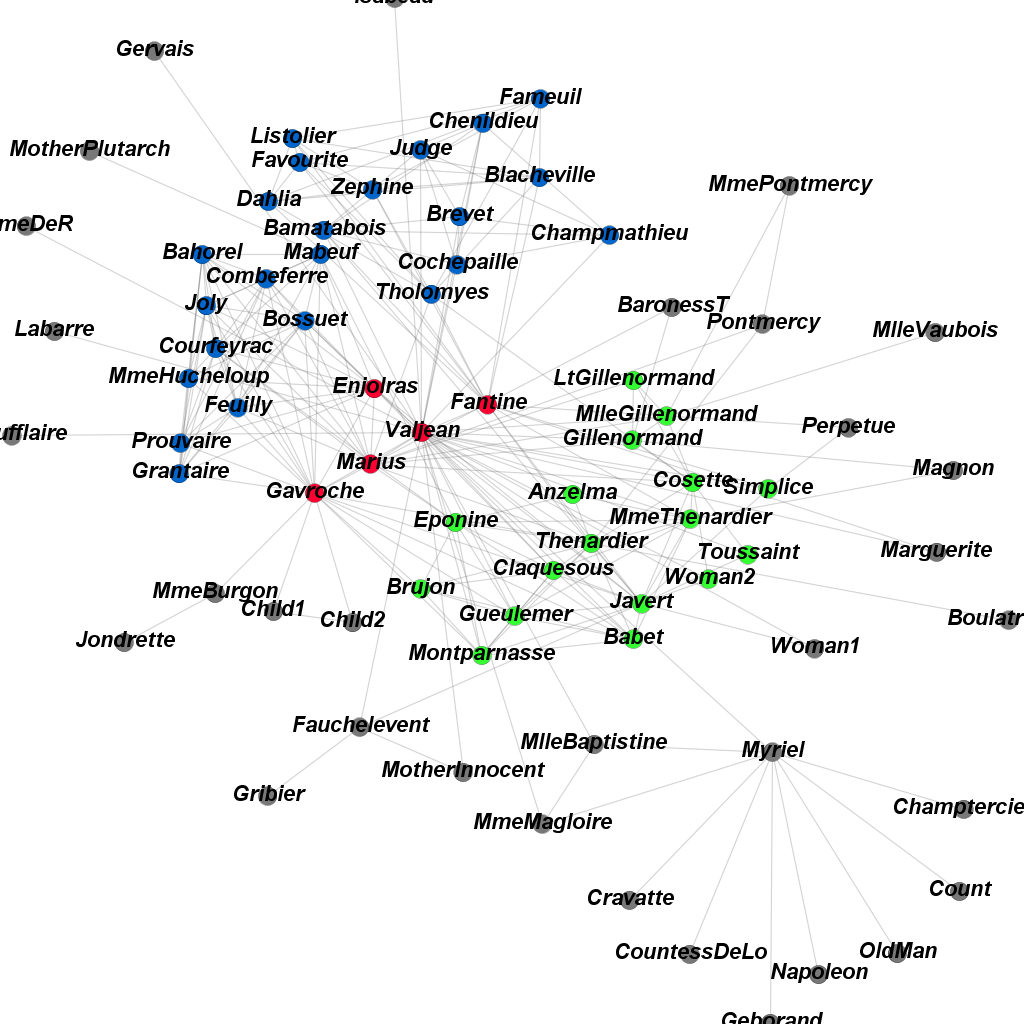
- Communities in the network of figures in the Les Miserables. The edge probability between two nodes not sharing a community is set to be 0.01 to detect more compact communities.:
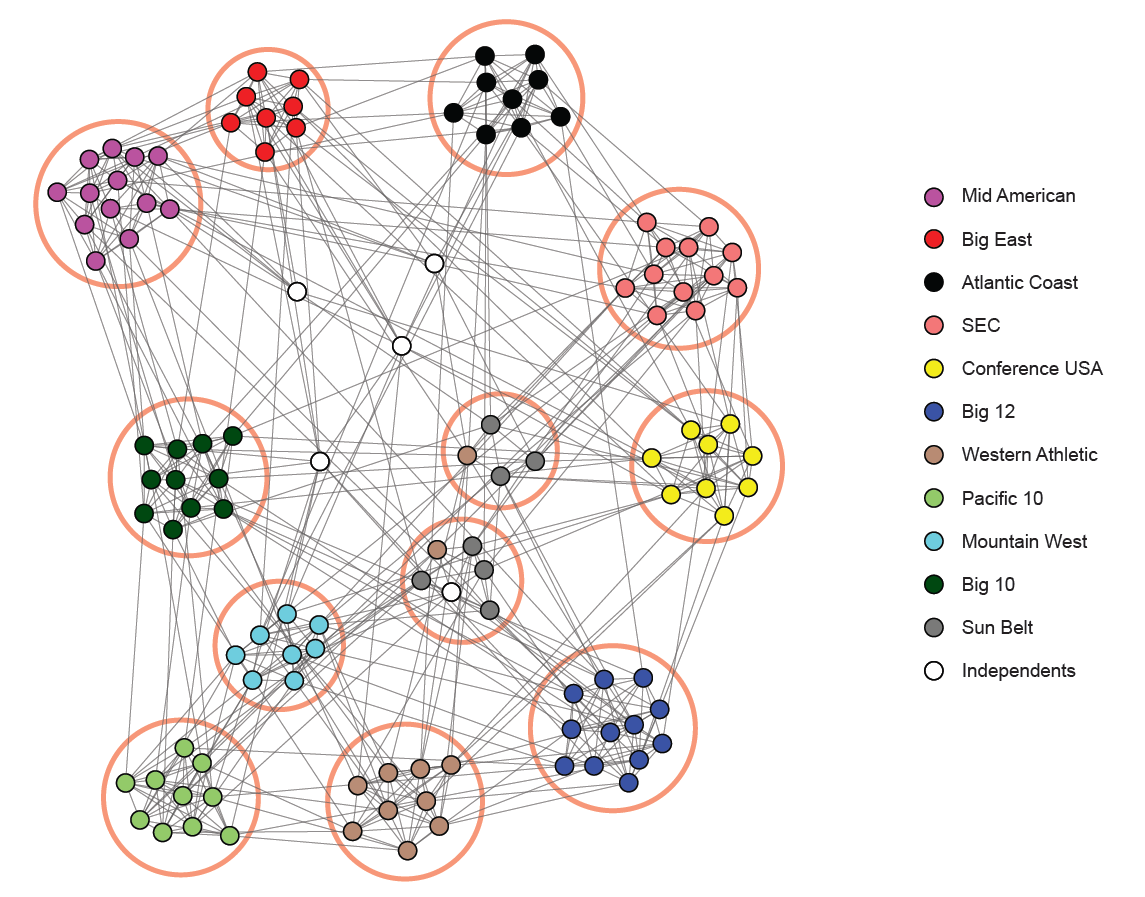
- Communities in NCAA football teams network (The best result with 5 trials with setting the edge probability of two nodes sharing no communities to be 0.1. Circular regions denote detected communities and node colors represent NCAA conferences.):
Download the code
We provide a C++ implementation of AGMfit in a comprehensive package with the necessary code from SNAP library.
Network Input format: Each line in an input file describes one edge by specifying the names of the two nodes having the edge. The two node names are separated by a tab:
Community Output format: AGMfit generates a text file (cmtyvv.txt) and a Graph Exchange XML file (graph.gexf). Each line of the text file specifies the name of member nodes of one community. The Graph Exchange XML format describes both the graph and the community memberships (specified by node attribute) and can be loaded in Gephi which supports filtering by communities (attributes in the Graph XML file).
Within the package, you can find additional information in ReadMe.txt, including how to compile and run AGMfit. We also provide some sample input data as a toy.
Download the data
We provide 6 data sets each of which have a network and a set of ground-truth communities. Ground-truth communities are communities that can be defined and identified from data. The webpage for each data set describes how we identify ground-truth communities in the data set.
Data sets:
| Name | Type | Nodes | Edges | Communities | Description |
|---|---|---|---|---|---|
| LiveJournal | Undirected, Communities | 3,997,962 | 34,681,189 | 664,414 | LiveJournal online social network |
| Friendster | Undirected, Communities | 65,608,366 | 1,806,067,135 | 1,620,991 | Friendster online social network |
| Orkut | Undirected, Communities | 3,072,441 | 117,185,083 | 15,301,901 | Orkut online social network |
| Youtube | Undirected, Communities | 1,134,890 | 2,987,624 | 16,386 | Youtube online social network |
| DBLP | Undirected, Communities | 317,080 | 1,049,866 | 13,477 | DBLP collaboration network |
| Amazon | Undirected, Communities | 334,863 | 925,872 | 271,570 | Amazon product network |