|
SNAP Library 2.1, Developer Reference
2013-09-25 10:47:25
SNAP, a general purpose, high performance system for analysis and manipulation of large networks
|
|
SNAP Library 2.1, Developer Reference
2013-09-25 10:47:25
SNAP, a general purpose, high performance system for analysis and manipulation of large networks
|
#include <unicode.h>
Classes | |
| class | TSubcatHelper |
| class | TUcdFileReader |
Public Types | |
| enum | { HangulSBase = 0xAC00, HangulLBase = 0x1100, HangulVBase = 0x1161, HangulTBase = 0x11A7, HangulLCount = 19, HangulVCount = 21, HangulTCount = 28, HangulNCount = HangulVCount * HangulTCount, HangulSCount = HangulLCount * HangulNCount } |
| enum | TCaseConversion_ { ccLower = 0, ccUpper = 1, ccTitle = 2, ccMax = 3 } |
| typedef enum TUniChDb::TCaseConversion_ | TCaseConversion |
Public Member Functions | |
| TUniChDb () | |
| TUniChDb (TSIn &SIn) | |
| void | Clr () |
| void | Save (TSOut &SOut) const |
| void | Load (TSIn &SIn) |
| void | LoadBin (const TStr &fnBin) |
| void | Test (const TStr &basePath) |
| const TStr & | GetScriptName (const int scriptId) const |
| int | GetScriptByName (const TStr &scriptName) const |
| int | GetScript (const TUniChInfo &ci) const |
| int | GetScript (const int cp) const |
| const char * | GetCharName (const int cp) const |
| TStr | GetCharNameS (const int cp) const |
| template<class TSrcVec > | |
| void | PrintCharNames (FILE *f, const TSrcVec &src, size_t srcIdx, const size_t srcCount, const TStr &prefix) const |
| template<class TSrcVec > | |
| void | PrintCharNames (FILE *f, const TSrcVec &src, const TStr &prefix) const |
| bool | IsGetChInfo (const int cp, TUniChInfo &ChInfo) |
| TUniChCategory | GetCat (const int cp) const |
| TUniChSubCategory | GetSubCat (const int cp) const |
| bool | IsWbFlag (const int cp, const TUniChFlags flag) const |
| int | GetWbFlags (const int cp) const |
| bool | IsSbFlag (const int cp, const TUniChFlags flag) const |
| int | GetSbFlags (const int cp) const |
| DECLARE_FORWARDED_PROPERTY_METHODS bool | IsPrivateUse (const int cp) const |
| bool | IsSurrogate (const int cp) const |
| int | GetCombiningClass (const int cp) const |
| template<typename TSrcVec > | |
| bool | FindNextWordBoundary (const TSrcVec &src, const size_t srcIdx, const size_t srcCount, size_t &position) const |
| template<typename TSrcVec > | |
| void | FindWordBoundaries (const TSrcVec &src, const size_t srcIdx, const size_t srcCount, TBoolV &dest) const |
| template<typename TSrcVec > | |
| bool | FindNextSentenceBoundary (const TSrcVec &src, const size_t srcIdx, const size_t srcCount, size_t &position) const |
| template<typename TSrcVec > | |
| void | FindSentenceBoundaries (const TSrcVec &src, const size_t srcIdx, const size_t srcCount, TBoolV &dest) const |
| void | SbEx_Clr () |
| template<class TSrcVec > | |
| void | SbEx_Add (const TSrcVec &v) |
| void | SbEx_Add (const TStr &s) |
| void | SbEx_AddUtf8 (const TStr &s) |
| int | SbEx_AddMulti (const TStr &words, const bool wordsAreUtf8=true) |
| void | SbEx_Set (const TUniTrie< TInt > &newTrie) |
| int | SbEx_SetStdEnglish () |
| template<typename TSrcVec , typename TDestCh > | |
| void | Decompose (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, bool compatibility, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | Decompose (const TSrcVec &src, TVec< TDestCh > &dest, bool compatibility, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | Compose (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | Compose (const TSrcVec &src, TVec< TDestCh > &dest, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | DecomposeAndCompose (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, bool compatibility, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | DecomposeAndCompose (const TSrcVec &src, TVec< TDestCh > &dest, bool compatibility, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| size_t | ExtractStarters (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| size_t | ExtractStarters (const TSrcVec &src, TVec< TDestCh > &dest, bool clrDest=true) const |
| template<typename TSrcVec > | |
| size_t | ExtractStarters (TSrcVec &src) const |
| void | LoadTxt (const TStr &basePath) |
| void | SaveBin (const TStr &fnBinUcd) |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetCaseConverted (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest, const TCaseConversion how, const bool turkic, const bool lithuanian) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetLowerCase (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest=true, const bool turkic=false, const bool lithuanian=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetUpperCase (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest=true, const bool turkic=false, const bool lithuanian=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetTitleCase (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest=true, const bool turkic=false, const bool lithuanian=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetLowerCase (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true, const bool turkic=false, const bool lithuanian=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetUpperCase (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true, const bool turkic=false, const bool lithuanian=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetTitleCase (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true, const bool turkic=false, const bool lithuanian=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleCaseConverted (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest, const TCaseConversion how) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleLowerCase (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleUpperCase (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleTitleCase (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleLowerCase (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleUpperCase (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleTitleCase (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true) const |
| template<typename TSrcVec > | |
| void | ToSimpleCaseConverted (TSrcVec &src, size_t srcIdx, const size_t srcCount, const TCaseConversion how) const |
| template<typename TSrcVec > | |
| void | ToSimpleUpperCase (TSrcVec &src, size_t srcIdx, const size_t srcCount) const |
| template<typename TSrcVec > | |
| void | ToSimpleLowerCase (TSrcVec &src, size_t srcIdx, const size_t srcCount) const |
| template<typename TSrcVec > | |
| void | ToSimpleTitleCase (TSrcVec &src, size_t srcIdx, const size_t srcCount) const |
| template<typename TSrcVec > | |
| void | ToSimpleUpperCase (TSrcVec &src) const |
| template<typename TSrcVec > | |
| void | ToSimpleLowerCase (TSrcVec &src) const |
| template<typename TSrcVec > | |
| void | ToSimpleTitleCase (TSrcVec &src) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetCaseFolded (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest, const bool full, const bool turkic=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetCaseFolded (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true, const bool full=true, const bool turkic=false) const |
| template<typename TSrcVec > | |
| void | ToCaseFolded (TSrcVec &src, size_t srcIdx, const size_t srcCount, const bool turkic=false) const |
| template<typename TSrcVec > | |
| void | ToCaseFolded (TSrcVec &src, const bool turkic=false) const |
Static Public Member Functions | |
| static TStr | GetCaseFoldingFn () |
| static TStr | GetSpecialCasingFn () |
| static TStr | GetUnicodeDataFn () |
| static TStr | GetCompositionExclusionsFn () |
| static TStr | GetScriptsFn () |
| static TStr | GetDerivedCorePropsFn () |
| static TStr | GetLineBreakFn () |
| static TStr | GetPropListFn () |
| static TStr | GetAuxiliaryDir () |
| static TStr | GetWordBreakTestFn () |
| static TStr | GetWordBreakPropertyFn () |
| static TStr | GetSentenceBreakTestFn () |
| static TStr | GetSentenceBreakPropertyFn () |
| static TStr | GetNormalizationTestFn () |
| static TStr | GetBinFn () |
| static TStr | GetScriptNameUnknown () |
| static TStr | GetScriptNameKatakana () |
| static TStr | GetScriptNameHiragana () |
Public Attributes | |
| THash< TInt, TUniChInfo > | h |
| TStrPool | charNames |
| TStrIntH | scripts |
| TIntV | decompositions |
| THash< TIntPr, TInt > | inverseDec |
| TUniCaseFolding | caseFolding |
| TIntIntVH | specialCasingLower |
| TIntIntVH | specialCasingUpper |
| TIntIntVH | specialCasingTitle |
| int | scriptUnknown |
Protected Types | |
| typedef TUniVecIdx | TVecIdx |
Protected Member Functions | |
| void | InitAfterLoad () |
| bool | IsWbIgnored (const int cp) const |
| template<typename TSrcVec > | |
| void | WbFindCurOrNextNonIgnored (const TSrcVec &src, size_t &position, const size_t srcEnd) const |
| template<typename TSrcVec > | |
| void | WbFindNextNonIgnored (const TSrcVec &src, size_t &position, const size_t srcEnd) const |
| template<typename TSrcVec > | |
| void | WbFindNextNonIgnoredS (const TSrcVec &src, size_t &position, const size_t srcEnd) const |
| template<typename TSrcVec > | |
| bool | WbFindPrevNonIgnored (const TSrcVec &src, const size_t srcStart, size_t &position) const |
| void | TestWbFindNonIgnored (const TIntV &src) const |
| void | TestWbFindNonIgnored () const |
| void | TestFindNextWordOrSentenceBoundary (const TStr &basePath, bool sentence) |
| template<typename TSrcVec > | |
| bool | CanSentenceEndHere (const TSrcVec &src, const size_t srcIdx, const size_t position) const |
| template<typename TDestCh > | |
| void | AddDecomposition (const int codePoint, TVec< TDestCh > &dest, const bool compatibility) const |
| void | TestComposition (const TStr &basePath) |
| void | InitWordAndSentenceBoundaryFlags (const TStr &basePath) |
| void | InitScripts (const TStr &basePath) |
| void | InitLineBreaks (const TStr &basePath) |
| void | InitDerivedCoreProperties (const TStr &basePath) |
| void | InitPropList (const TStr &basePath) |
| void | InitSpecialCasing (const TStr &basePath) |
| void | LoadTxt_ProcessDecomposition (TUniChInfo &ci, TStr s) |
| void | TestCaseConversion (const TStr &source, const TStr &trueLc, const TStr &trueTc, const TStr &trueUc, bool turkic, bool lithuanian) |
| void | TestCaseConversions () |
Static Protected Member Functions | |
| static bool | IsWbIgnored (const TUniChInfo &ci) |
Protected Attributes | |
| TUniTrie< TInt > | sbExTrie |
Friends | |
| class | TUniCaseFolding |
| typedef enum TUniChDb::TCaseConversion_ TUniChDb::TCaseConversion |
typedef TUniVecIdx TUniChDb::TVecIdx [protected] |
| anonymous enum |
| HangulSBase | |
| HangulLBase | |
| HangulVBase | |
| HangulTBase | |
| HangulLCount | |
| HangulVCount | |
| HangulTCount | |
| HangulNCount | |
| HangulSCount |
Definition at line 1405 of file unicode.h.
{
HangulSBase = 0xAC00, HangulLBase = 0x1100, HangulVBase = 0x1161, HangulTBase = 0x11A7,
HangulLCount = 19, HangulVCount = 21, HangulTCount = 28,
HangulNCount = HangulVCount * HangulTCount, // 588
HangulSCount = HangulLCount * HangulNCount // 11172
};
| TUniChDb::TUniChDb | ( | ) | [inline] |
Definition at line 1274 of file unicode.h.
Referenced by Test().
: scriptUnknown(-1) { }

| TUniChDb::TUniChDb | ( | TSIn & | SIn | ) | [inline, explicit] |
| void TUniChDb::AddDecomposition | ( | const int | codePoint, |
| TVec< TDestCh > & | dest, | ||
| const bool | compatibility | ||
| ) | const [protected] |
Definition at line 3097 of file unicode.h.
References TVec< TVal, TSizeTy >::Add(), TUniChInfo::decompOffset, decompositions, THash< TKey, TDat, THashFunc >::GetKeyId(), h, HangulLBase, HangulNCount, HangulSBase, HangulSCount, HangulTBase, HangulTCount, HangulVBase, and TUniChInfo::IsCompatibilityDecomposition().
Referenced by Decompose().
{
if (HangulSBase <= codePoint && codePoint < HangulSBase + HangulSCount)
{
// UAX #15, sec. 16: Hangul decomposition
const int SIndex = codePoint - HangulSBase;
const int L = HangulLBase + SIndex / HangulNCount;
const int V = HangulVBase + (SIndex % HangulNCount) / HangulTCount;
const int T = HangulTBase + (SIndex % HangulTCount);
dest.Add(L); dest.Add(V);
if (T != HangulTBase) dest.Add(T);
return;
}
int i = h.GetKeyId(codePoint); if (i < 0) { dest.Add(codePoint); return; }
const TUniChInfo &ci = h[i];
int ofs = ci.decompOffset; if (ofs < 0) { dest.Add(codePoint); return; }
if ((! compatibility) && ci.IsCompatibilityDecomposition()) { dest.Add(codePoint); return; }
while (true) {
int cp = decompositions[ofs++]; if (cp < 0) return;
AddDecomposition(cp, dest, compatibility); }
}
| bool TUniChDb::CanSentenceEndHere | ( | const TSrcVec & | src, |
| const size_t | srcIdx, | ||
| const size_t | position | ||
| ) | const [protected] |
Definition at line 2582 of file unicode.h.
References TUniTrie< TItem_ >::Empty(), TUniTrie< TItem_ >::Get3GramRoot(), GetCat(), TUniTrie< TItem_ >::GetChild(), GetSbFlags(), TUniTrie< TItem_ >::Has1Gram(), TUniTrie< TItem_ >::Has2Gram(), IAssert, TUniTrie< TItem_ >::IsNodeTerminal(), sbExTrie, ucfSbATerm, ucfSbSep, ucfSbSp, ucfSbSTerm, and WbFindPrevNonIgnored().
Referenced by FindNextSentenceBoundary().
{
if (sbExTrie.Empty()) return true;
// We'll move back from the position where a sentence-boundary is being considered.
size_t pos = position;
if (! WbFindPrevNonIgnored(src, srcIdx, pos)) return true;
int c = (int) src[TVecIdx(pos)]; int sfb = GetSbFlags(c);
// - Skip the Sep, if there is one.
if ((c & ucfSbSep) == ucfSbSep) {
if (! WbFindPrevNonIgnored(src, srcIdx, pos)) return true;
c = (int) src[TVecIdx(pos)]; sfb = GetSbFlags(c); }
// - Skip any Sp characters.
while ((sfb & ucfSbSp) == ucfSbSp) {
if (! WbFindPrevNonIgnored(src, srcIdx, pos)) return true;
c = (int) src[TVecIdx(pos)]; sfb = GetSbFlags(c); }
// - Skip any Close characters.
while ((sfb & ucfSbSp) == ucfSbSp) {
if (! WbFindPrevNonIgnored(src, srcIdx, pos)) return true;
c = (int) src[TVecIdx(pos)]; sfb = GetSbFlags(c); }
// - Skip any ATerm | STerm characters.
while ((sfb & (ucfSbATerm | ucfSbSTerm)) != 0) {
if (! WbFindPrevNonIgnored(src, srcIdx, pos)) return true;
c = (int) src[TVecIdx(pos)]; sfb = GetSbFlags(c); }
// Now start moving through the trie.
int cLast = c, cButLast = -1, cButButLast = -1, len = 1, node = -1;
while (true)
{
bool atEnd = (! WbFindPrevNonIgnored(src, srcIdx, pos));
c = (atEnd ? -1 : (int) src[TVecIdx(pos)]);
TUniChCategory cat = GetCat(c);
if (atEnd || ! (cat == ucLetter || cat == ucNumber || cat == ucSymbol)) {
// Check if the suffix we've read so far is one of those that appear in the trie.
if (len == 1) return ! sbExTrie.Has1Gram(cLast);
if (len == 2) return ! sbExTrie.Has2Gram(cLast, cButLast);
IAssert(len >= 3); IAssert(node >= 0);
if (sbExTrie.IsNodeTerminal(node)) return false;
if (atEnd) return true; }
if (len == 1) { cButLast = c; len++; }
else if (len == 2) { cButButLast = c; len++;
// Now we have read the last three characters; start descending the suitable subtrie.
node = sbExTrie.Get3GramRoot(cLast, cButLast, cButButLast);
if (node < 0) return true; }
else {
// Descend down the trie.
node = sbExTrie.GetChild(node, c);
if (node < 0) return true; }
}
//return true;
}

| void TUniChDb::Clr | ( | ) | [inline] |
Definition at line 1276 of file unicode.h.
References caseFolding, charNames, THash< TKey, TDat, THashFunc >::Clr(), TUniCaseFolding::Clr(), TVec< TVal, TSizeTy >::Clr(), TStrPool::Clr(), decompositions, h, inverseDec, scripts, specialCasingLower, specialCasingTitle, and specialCasingUpper.
Referenced by LoadTxt().
{
h.Clr(); charNames.Clr(); decompositions.Clr(); inverseDec.Clr(); caseFolding.Clr();
specialCasingLower.Clr(); specialCasingUpper.Clr(); specialCasingTitle.Clr();
scripts.Clr(); }

| void TUniChDb::Compose | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| bool | clrDest = true |
||
| ) | const |
Definition at line 3152 of file unicode.h.
References TVec< TVal, TSizeTy >::Add(), Assert, ccMax, TUniChInfo::ccStarter, TVec< TVal, TSizeTy >::Clr(), GetCombiningClass(), THash< TKey, TDat, THashFunc >::GetKeyId(), HangulLBase, HangulLCount, HangulSBase, HangulSCount, HangulTBase, HangulTCount, HangulVBase, HangulVCount, inverseDec, and TVec< TVal, TSizeTy >::Len().
Referenced by Compose(), TUnicode::Compose(), and DecomposeAndCompose().
{
if (clrDest) dest.Clr();
bool lastStarterKnown = false; // has a starter been encountered yet?
size_t lastStarterPos = size_t(-1); // the index (in 'dest') of the last starter
int cpLastStarter = -1; // the codepoint of the last starter (i.e. cpLastStarter == dest[lastStarterPos])
const size_t srcEnd = srcIdx + srcCount;
int ccMax = -1; // The highest combining class among the characters since the last starter.
while (srcIdx < srcEnd)
{
const int cp = src[TVecIdx(srcIdx)]; srcIdx++;
const int cpClass = GetCombiningClass(cp);
//int cpCombined = -1;
// If there is a starter with which 'cp' can be combined, and from which it is not blocked
// by some intermediate character, we can try to combine them.
if (lastStarterKnown && ccMax < cpClass)
{
int j = inverseDec.GetKeyId(TIntPr(cpLastStarter, cp));
int cpCombined = -1;
do {
// Try to look up a composition in the inverseDec table.
if (j >= 0) { cpCombined = inverseDec[j]; break; }
// UAX #15, sec. 16: Hangul composition
// - Try to combine L and V.
const int LIndex = cpLastStarter - HangulLBase;
if (0 <= LIndex && LIndex < HangulLCount) {
const int VIndex = cp - HangulVBase;
if (0 <= VIndex && VIndex < HangulVCount) {
cpCombined = HangulSBase + (LIndex * HangulVCount + VIndex) * HangulTCount;
break; } }
// - Try to combine LV and T.
const int SIndex = cpLastStarter - HangulSBase;
if (0 <= SIndex && SIndex < HangulSCount && (SIndex % HangulTCount) == 0)
{
const int TIndex = cp - HangulTBase;
if (0 <= TIndex && TIndex < HangulTCount) {
cpCombined = cpLastStarter + TIndex;
break; }
}
} while (false);
// If a combining character has been found, use it to replace the old cpStarter.
if (cpCombined >= 0) {
dest[TVecIdx(lastStarterPos)] = cpCombined;
Assert(GetCombiningClass(cpCombined) == TUniChInfo::ccStarter);
// if (cpCombined is not a starter) { starterKnown = false; lastStarterPos = size_t(01); cpLastStarter = -1; } else
cpLastStarter = cpCombined; continue; }
}
if (cpClass == TUniChInfo::ccStarter) { // 'cp' is a starter, remember it for later. Set ccMax to -1 so that this starter can be combined with another starter.
lastStarterKnown = true; lastStarterPos = dest.Len(); cpLastStarter = cp; ccMax = cpClass - 1; }
else if (cpClass > ccMax) // Remember cp's class as the new maximum class since the last starter (for blocking).
ccMax = cpClass;
dest.Add(cp);
}
}

| void TUniChDb::Compose | ( | const TSrcVec & | src, |
| TVec< TDestCh > & | dest, | ||
| bool | clrDest = true |
||
| ) | const [inline] |
| void TUniChDb::Decompose | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| bool | compatibility, | ||
| bool | clrDest = true |
||
| ) | const |
Definition at line 3120 of file unicode.h.
References AddDecomposition(), TUniChInfo::ccStarter, TVec< TVal, TSizeTy >::Clr(), GetCombiningClass(), and TVec< TVal, TSizeTy >::Len().
Referenced by Decompose(), TUnicode::Decompose(), and DecomposeAndCompose().
{
if (clrDest) dest.Clr();
const size_t destStart = dest.Len()/*, srcEnd = srcIdx + srcCount*/;
// Decompose the string.
while (srcIdx < srcCount) {
AddDecomposition(src[TVecIdx(srcIdx)], dest, compatibility); srcIdx++; }
// Rearrange the decomposed string into canonical order.
for (size_t destIdx = destStart, destEnd = dest.Len(); destIdx < destEnd; )
{
size_t j = destIdx;
int cp = dest[TVecIdx(destIdx)]; destIdx++;
int cpCls = GetCombiningClass(cp);
if (cpCls == TUniChInfo::ccStarter) continue;
while (destStart < j && GetCombiningClass(dest[TVecIdx(j - 1)]) > cpCls) {
dest[TVecIdx(j)] = dest[TVecIdx(j - 1)]; j--; }
dest[TVecIdx(j)] = cp;
}
}
| void TUniChDb::Decompose | ( | const TSrcVec & | src, |
| TVec< TDestCh > & | dest, | ||
| bool | compatibility, | ||
| bool | clrDest = true |
||
| ) | const [inline] |
Definition at line 1520 of file unicode.h.
References Decompose().
{
Decompose(src, 0, src.Len(), dest, compatibility, clrDest); }
| void TUniChDb::DecomposeAndCompose | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| bool | compatibility, | ||
| bool | clrDest = true |
||
| ) | const |
Definition at line 3142 of file unicode.h.
References TVec< TVal, TSizeTy >::Clr(), Compose(), Decompose(), and TVec< TVal, TSizeTy >::Len().
Referenced by DecomposeAndCompose(), and TUnicode::DecomposeAndCompose().
{
if (clrDest) dest.Clr();
TIntV temp;
Decompose(src, srcIdx, srcCount, temp, compatibility);
Compose(temp, 0, temp.Len(), dest, clrDest);
}


| void TUniChDb::DecomposeAndCompose | ( | const TSrcVec & | src, |
| TVec< TDestCh > & | dest, | ||
| bool | compatibility, | ||
| bool | clrDest = true |
||
| ) | const [inline] |
Definition at line 1542 of file unicode.h.
References DecomposeAndCompose().
{
DecomposeAndCompose(src, 0, src.Len(), dest, compatibility, clrDest); }
| size_t TUniChDb::ExtractStarters | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| bool | clrDest = true |
||
| ) | const |
Definition at line 3209 of file unicode.h.
References TVec< TVal, TSizeTy >::Add(), TUniChInfo::ccStarter, TVec< TVal, TSizeTy >::Clr(), and GetCombiningClass().
Referenced by ExtractStarters(), and TUnicode::ExtractStarters().
{
if (clrDest) dest.Clr();
size_t retVal = 0;
for (const size_t srcEnd = srcIdx + srcCount; srcIdx < srcEnd; srcIdx++) {
const int cp = src[TVecIdx(srcIdx)];
if (GetCombiningClass(cp) == TUniChInfo::ccStarter)
{ dest.Add(cp); retVal++; } }
return retVal;
}
| size_t TUniChDb::ExtractStarters | ( | const TSrcVec & | src, |
| TVec< TDestCh > & | dest, | ||
| bool | clrDest = true |
||
| ) | const [inline] |
Definition at line 1551 of file unicode.h.
References ExtractStarters().
{
return ExtractStarters(src, 0, src.Len(), dest, clrDest); }

| size_t TUniChDb::ExtractStarters | ( | TSrcVec & | src | ) | const [inline] |
Definition at line 1555 of file unicode.h.
References ExtractStarters(), and TVec< TVal, TSizeTy >::Len().
{
TIntV temp; size_t retVal = ExtractStarters(src, temp);
src.Clr(); for (int i = 0; i < temp.Len(); i++) src.Add(temp[i]);
return retVal; }

| bool TUniChDb::FindNextSentenceBoundary | ( | const TSrcVec & | src, |
| const size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| size_t & | position | ||
| ) | const |
Definition at line 2633 of file unicode.h.
References CanSentenceEndHere(), GetSbFlags(), IAssert, IsPeekAheadSkippable, IsWbIgnored(), TestCurNext, TestPrevCurNext, Trans, ucfSbATerm, ucfSbClose, ucfSbLower, ucfSbNumeric, ucfSbSep, ucfSbSp, ucfSbSTerm, ucfSbUpper, WbFindNextNonIgnored(), and WbFindPrevNonIgnored().
Referenced by TUnicode::FindNextSentenceBoundary(), FindSentenceBoundaries(), and TestFindNextWordOrSentenceBoundary().
{
// SB1. Break at the start of text.
if (position < srcIdx) { position = srcIdx; return true; }
// If we are beyond the end of the text, there aren't any word breaks left.
const size_t srcEnd = srcIdx + srcCount;
if (position >= srcEnd) return false;
// If 'position' is currently at an ignored character, move it back to the last nonignored character.
size_t origPos = position;
if (IsWbIgnored(src[TVecIdx(position)])) {
if (! WbFindPrevNonIgnored(src, srcIdx, position))
position = origPos;
}
// Determine the previous nonignored character (before 'position').
size_t posPrev = position;
if (! WbFindPrevNonIgnored(src, srcIdx, posPrev)) posPrev = position;
// Sec 6.2. Allow a break between Sep and an ignored character.
if (position == origPos && position + 1 < srcEnd && IsSbSep(src[TVecIdx(position)]) && IsWbIgnored(src[TVecIdx(position + 1)])) { position += 1; return true; }
// Determine the next nonignored character (after 'position').
size_t posNext = position; WbFindNextNonIgnored(src, posNext, srcEnd);
size_t posNext2;
int cPrev = (posPrev < position ? (int) src[TVecIdx(posPrev)] : -1), cCur = (position < srcEnd ? (int) src[TVecIdx(position)] : -1);
int cNext = (position < posNext && posNext < srcEnd ? (int) src[TVecIdx(posNext)] : -1);
int sbfPrev = GetSbFlags(cPrev), sbfCur = GetSbFlags(cCur), sbfNext = GetSbFlags(cNext);
int cNext2, sbfNext2;
// Initialize the state of the peek-back automaton.
typedef enum { stInit, stATerm, stATermSp, stATermSep, stSTerm, stSTermSp, stSTermSep } TPeekBackState;
TPeekBackState backState;
{
size_t pos = position;
bool wasSep = false, wasSp = false, wasATerm = false, wasSTerm = false;
while (true)
{
if (! WbFindPrevNonIgnored(src, srcIdx, pos)) break;
// Skip at most one Sep.
int cp = (int) src[TVecIdx(pos)]; int sbf = GetSbFlags(cp);
if ((sbf & ucfSbSep) == ucfSbSep) {
wasSep = true;
if (! WbFindPrevNonIgnored(src, srcIdx, pos)) break;
cp = (int) src[TVecIdx(pos)]; sbf = GetSbFlags(cp); }
// Skip zero or more Sp's.
bool stop = false;
while ((sbf & ucfSbSp) == ucfSbSp) {
wasSp = true;
if (! WbFindPrevNonIgnored(src, srcIdx, pos)) { stop = true; break; }
cp = (int) src[TVecIdx(pos)]; sbf = GetSbFlags(cp); }
if (stop) break;
// Skip zero or more Close's.
while ((sbf & ucfSbClose) == ucfSbClose) {
if (! WbFindPrevNonIgnored(src, srcIdx, pos)) { stop = true; break; }
cp = (int) src[TVecIdx(pos)]; sbf = GetSbFlags(cp); }
if (stop) break;
// Process an ATerm or STerm.
wasATerm = ((sbf & ucfSbATerm) == ucfSbATerm);
wasSTerm = ((sbf & ucfSbSTerm) == ucfSbSTerm);
break;
}
if (wasATerm) backState = (wasSep ? stATermSep : wasSp ? stATermSp : stATerm);
else if (wasSTerm) backState = (wasSep ? stSTermSep : wasSp ? stSTermSp : stSTerm);
else backState = stInit;
}
// Initialize the state of the peek-ahead automaton. This state tells us what follows
// after we skip all contiguous characters from the complement of the set {OLetter, Upper, Lower, Sep, STerm, ATerm}.
// Thus, the next character is either OLetter, Upper, Lower, Sep, STerm, ATerm, or the end of the input string.
// Our peek-ahead automaton must tell us whether it is Lower or something else.
typedef enum { stUnknown, stLower, stNotLower } TPeekAheadState;
TPeekAheadState aheadState = stUnknown;
//
for ( ; position < srcEnd; posPrev = position, position = posNext, posNext = posNext2,
cPrev = cCur, cCur = cNext, cNext = cNext2,
sbfPrev = sbfCur, sbfCur = sbfNext, sbfNext = sbfNext2)
{
// Should there be a word boundary between 'position' and 'posNext' (or, more accurately,
// between src[posNext - 1] and src[posNext] --- any ignored characters between 'position'
// and 'posNext' are considered to belong to the previous character ('position'), not to the next one)?
posNext2 = posNext; WbFindNextNonIgnored(src, posNext2, srcEnd);
cNext2 = (posNext < posNext2 && posNext2 < srcEnd ? (int) src[TVecIdx(posNext2)] : -1);
sbfNext2 = GetSbFlags(cNext2);
// Update the peek-back automaton.
#define TestCur(curFlag) ((sbfCur & ucfSb##curFlag) == ucfSb##curFlag)
#define Trans(curFlag, newState) if (TestCur(curFlag)) { backState = st##newState; break; }
switch (backState) {
case stInit: Trans(ATerm, ATerm); Trans(STerm, STerm); break;
case stATerm: Trans(Sp, ATermSp); Trans(Sep, ATermSep); Trans(ATerm, ATerm); Trans(STerm, STerm); Trans(Close, ATerm); backState = stInit; break;
case stSTerm: Trans(Sp, STermSp); Trans(Sep, STermSep); Trans(ATerm, ATerm); Trans(STerm, STerm); Trans(Close, STerm); backState = stInit; break;
case stATermSp: Trans(Sp, ATermSp); Trans(Sep, ATermSep); Trans(ATerm, ATerm); Trans(STerm, STerm); backState = stInit; break;
case stSTermSp: Trans(Sp, STermSp); Trans(Sep, STermSep); Trans(ATerm, ATerm); Trans(STerm, STerm); backState = stInit; break;
case stATermSep: Trans(ATerm, ATerm); Trans(STerm, STerm); backState = stInit; break;
case stSTermSep: Trans(ATerm, ATerm); Trans(STerm, STerm); backState = stInit; break;
default: IAssert(false); }
#undef Trans
#undef TestCur
// Update the peek-ahead automaton.
#define IsPeekAheadSkippable(sbf) ((sbf & (ucfSbOLetter | ucfSbUpper | ucfSbLower | ucfSbSep | ucfSbSTerm | ucfSbATerm)) == 0)
if (! IsPeekAheadSkippable(sbfCur)) {
bool isLower = ((sbfCur & ucfSbLower) == ucfSbLower);
if (aheadState == stLower) IAssert(isLower);
else if (aheadState == stNotLower) IAssert(! isLower);
// We haven't peaked ahead farther than this so far -- invalidate the state.
aheadState = stUnknown; }
if (aheadState == stUnknown)
{
// Peak ahead to the next non-peekahead-skippable character.
size_t pos = posNext;
while (pos < srcEnd) {
int cp = (int) src[TVecIdx(pos)]; int sbf = GetSbFlags(cp);
if (! IsPeekAheadSkippable(sbf)) {
if ((sbf & ucfSbLower) == ucfSbLower) aheadState = stLower;
else aheadState = stNotLower;
break; }
WbFindNextNonIgnored(src, pos, srcEnd); }
if (! (pos < srcEnd)) aheadState = stNotLower;
}
#undef IsPeekAheadSkippable
//
#define TestCurNext(curFlag, nextFlag) if ((sbfCur & curFlag) == curFlag && (sbfNext & nextFlag) == nextFlag) continue
#define TestCurNext2(curFlag, nextFlag, next2Flag) if ((sbfCur & curFlag) == curFlag && (sbfNext & nextFlag) == nextFlag && (sbfNext2 & next2Flag) == next2Flag) continue
#define TestPrevCurNext(prevFlag, curFlag, nextFlag) if ((sbfPrev & prevFlag) == prevFlag && (sbfCur & curFlag) == curFlag && (sbfNext & nextFlag) == nextFlag) continue
// SB3. Do not break within CRLF.
if (cCur == 13 && cNext == 10) continue;
// SB4. Break ater paragraph separators.
if ((sbfCur & ucfSbSep) == ucfSbSep) {
if (! CanSentenceEndHere(src, srcIdx, position)) continue;
position = posNext; return true; }
// Do not break after ambiguous terminators like period, if they are immediately followed by a number
// or lowercase letter, if they are between uppercase letters, or if the first following letter
// (optionally after certain punctuation) is lowercase. For example, a period may be an abbreviation
// or numeric period, and thus may not mark the end of a sentence.
TestCurNext(ucfSbATerm, ucfSbNumeric); // SB6
TestPrevCurNext(ucfSbUpper, ucfSbATerm, ucfSbUpper); // SB7
// SB8a. (STerm | ATerm) Close* Sp* [do not break] (STerm | ATerm)
if ((backState == stATerm || backState == stATermSp || backState == stSTerm || backState == stSTermSp) &&
(sbfNext & (ucfSbSTerm | ucfSbATerm)) != 0) continue;
// SB8*. ATerm Close* Sp* [do not break] ( ! (OLetter | Upper | Lower | Sep | STerm | ATerm) )* Lower
if ((backState == stATerm || backState == stATermSp) && aheadState == stLower) continue;
// Break after sentence terminators, but include closing punctuation, trailing spaces, and a paragraph separator (if present).
// SB9. ( STerm | ATerm ) Close* [do not break] ( Close | Sp | Sep )
if ((backState == stATerm || backState == stSTerm) && (sbfNext & (ucfSbClose | ucfSbSp | ucfSbSep)) != 0) continue;
// SB10. ( STerm | ATerm ) Close* Sp* [do not break] ( Sp | Sep )
// SB11*. ( STerm | ATerm ) Close* Sp* Sep? [do break]
if (backState == stATerm || backState == stATermSp || backState == stATermSep || backState == stSTerm || backState == stSTermSp || backState == stSTermSep) {
if ((sbfNext & (ucfSbSp | ucfSbSep)) != 0) continue; // SB10
if (! CanSentenceEndHere(src, srcIdx, position)) continue;
position = posNext; return true; } // SB11
// WB12. Otherwise, do not break.
continue;
#undef TestCurNext
#undef TestCurNext2
#undef TestPrevCurNext
}
// WB2. Break at the end of text.
IAssert(position == srcEnd);
return true;
}

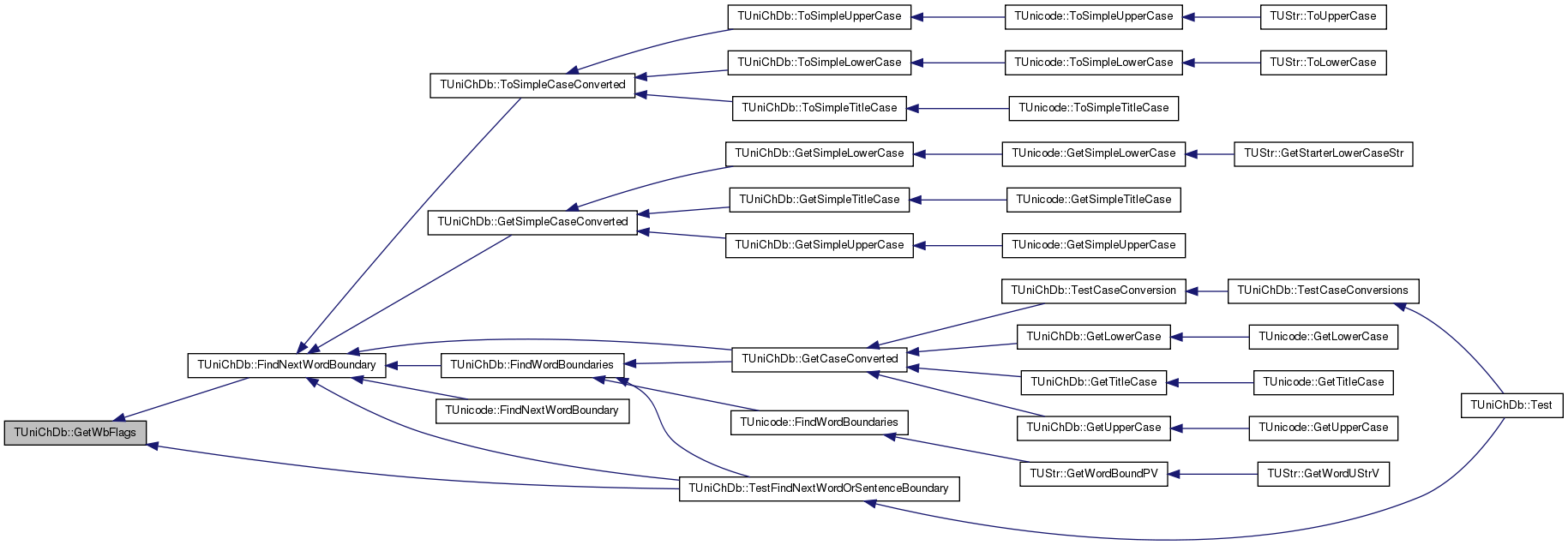
| bool TUniChDb::FindNextWordBoundary | ( | const TSrcVec & | src, |
| const size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| size_t & | position | ||
| ) | const |
Definition at line 2483 of file unicode.h.
References GetWbFlags(), IAssert, IsWbIgnored(), TestCurNext, TestCurNext2, TestPrevCurNext, ucfWbALetter, ucfWbExtendNumLet, ucfWbKatakana, ucfWbMidLetter, ucfWbMidNum, ucfWbNumeric, WbFindNextNonIgnored(), and WbFindPrevNonIgnored().
Referenced by TUnicode::FindNextWordBoundary(), FindWordBoundaries(), GetCaseConverted(), GetSimpleCaseConverted(), TestFindNextWordOrSentenceBoundary(), and ToSimpleCaseConverted().
{
// WB1. Break at the start of text.
if (position < srcIdx) { position = srcIdx; return true; }
// If we are beyond the end of the text, there aren't any word breaks left.
const size_t srcEnd = srcIdx + srcCount;
if (position >= srcEnd) return false;
// If 'position' is currently at an ignored character, move it back to the last nonignored character.
size_t origPos = position;
if (IsWbIgnored(src[TVecIdx(position)])) {
if (! WbFindPrevNonIgnored(src, srcIdx, position))
position = origPos;
}
// Determine the previous nonignored character (before 'position').
size_t posPrev = position;
if (! WbFindPrevNonIgnored(src, srcIdx, posPrev)) posPrev = position;
// Sec 6.2. Allow a break between Sep and an ignored character.
if (position == origPos && position + 1 < srcEnd && IsSbSep(src[TVecIdx(position)]) && IsWbIgnored(src[TVecIdx(position + 1)])) { position += 1; return true; }
// Determine the next nonignored character (after 'position').
size_t posNext = position; WbFindNextNonIgnored(src, posNext, srcEnd);
size_t posNext2;
int cPrev = (posPrev < position ? (int) src[TVecIdx(posPrev)] : -1), cCur = (position < srcEnd ? (int) src[TVecIdx(position)] : -1);
int cNext = (position < posNext && posNext < srcEnd ? (int) src[TVecIdx(posNext)] : -1);
int wbfPrev = GetWbFlags(cPrev), wbfCur = GetWbFlags(cCur), wbfNext = GetWbFlags(cNext);
int cNext2, wbfNext2;
//
for ( ; position < srcEnd; posPrev = position, position = posNext, posNext = posNext2,
cPrev = cCur, cCur = cNext, cNext = cNext2,
wbfPrev = wbfCur, wbfCur = wbfNext, wbfNext = wbfNext2)
{
// Should there be a word boundary between 'position' and 'posNext' (or, more accurately,
// between src[posNext - 1] and src[posNext] --- any ignored characters between 'position'
// and 'posNext' are considered to belong to the previous character ('position'), not to the next one)?
posNext2 = posNext; WbFindNextNonIgnored(src, posNext2, srcEnd);
cNext2 = (posNext < posNext2 && posNext2 < srcEnd ? (int) src[TVecIdx(posNext2)] : -1);
wbfNext2 = GetWbFlags(cNext2);
#define TestCurNext(curFlag, nextFlag) if ((wbfCur & curFlag) == curFlag && (wbfNext & nextFlag) == nextFlag) continue
#define TestCurNext2(curFlag, nextFlag, next2Flag) if ((wbfCur & curFlag) == curFlag && (wbfNext & nextFlag) == nextFlag && (wbfNext2 & next2Flag) == next2Flag) continue
#define TestPrevCurNext(prevFlag, curFlag, nextFlag) if ((wbfPrev & prevFlag) == prevFlag && (wbfCur & curFlag) == curFlag && (wbfNext & nextFlag) == nextFlag) continue
// WB3. Do not break within CRLF.
if (cCur == 13 && cNext == 10) continue;
// WB5. Do not break between most letters.
TestCurNext(ucfWbALetter, ucfWbALetter);
// WB6. Do not break letters across certain punctuation.
TestCurNext2(ucfWbALetter, ucfWbMidLetter, ucfWbALetter);
// WB7. Do not break letters across certain punctuation.
TestPrevCurNext(ucfWbALetter, ucfWbMidLetter, ucfWbALetter);
// WB8. Do not break within sequences of digits, or digits adjacent to letters.
TestCurNext(ucfWbNumeric, ucfWbNumeric);
// WB9. Do not break within sequences of digits, or digits adjacent to letters.
TestCurNext(ucfWbALetter, ucfWbNumeric);
// WB10. Do not break within sequences of digits, or digits adjacent to letters.
TestCurNext(ucfWbNumeric, ucfWbALetter);
// WB11. Do not break within sequences, such as "3.2" or "3.456,789".
TestPrevCurNext(ucfWbNumeric, ucfWbMidNum, ucfWbNumeric);
// WB12. Do not break within sequences, such as "3.2" or "3.456,789".
TestCurNext2(ucfWbNumeric, ucfWbMidNum, ucfWbNumeric);
// WB13. Do not break between Katakana.
TestCurNext(ucfWbKatakana, ucfWbKatakana);
// WB13a. Do not break from extenders.
if ((wbfCur & (ucfWbALetter | ucfWbNumeric | ucfWbKatakana | ucfWbExtendNumLet)) != 0 &&
(wbfNext & ucfWbExtendNumLet) == ucfWbExtendNumLet) continue;
// WB13b. Do not break from extenders.
if ((wbfCur & ucfWbExtendNumLet) == ucfWbExtendNumLet &&
(wbfNext & (ucfWbALetter | ucfWbNumeric | ucfWbKatakana)) != 0) continue;
// WB14. Otherwise, break everywhere.
position = posNext; return true;
#undef TestCurNext
#undef TestCurNext2
#undef TestPrevCurNext
}
// WB2. Break at the end of text.
IAssert(position == srcEnd);
return true;
}

| void TUniChDb::FindSentenceBoundaries | ( | const TSrcVec & | src, |
| const size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TBoolV & | dest | ||
| ) | const |
Definition at line 2790 of file unicode.h.
References Assert, FindNextSentenceBoundary(), TVec< TVal, TSizeTy >::Gen(), TVec< TVal, TSizeTy >::Len(), and TVec< TVal, TSizeTy >::PutAll().
Referenced by TUnicode::FindSentenceBoundaries(), and TestFindNextWordOrSentenceBoundary().
{
if (size_t(dest.Len()) != srcCount + 1) dest.Gen(TVecIdx(srcCount + 1));
dest.PutAll(false);
size_t position = srcIdx;
dest[TVecIdx(position - srcIdx)] = true;
while (position < srcIdx + srcCount)
{
size_t oldPos = position;
FindNextSentenceBoundary(src, srcIdx, srcCount, position);
Assert(oldPos < position); Assert(position <= srcIdx + srcCount);
dest[TVecIdx(position - srcIdx)] = true;
}
Assert(dest[TVecIdx(srcCount)]);
}


| void TUniChDb::FindWordBoundaries | ( | const TSrcVec & | src, |
| const size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TBoolV & | dest | ||
| ) | const |
Definition at line 2561 of file unicode.h.
References Assert, FindNextWordBoundary(), TVec< TVal, TSizeTy >::Gen(), TVec< TVal, TSizeTy >::Len(), and TVec< TVal, TSizeTy >::PutAll().
Referenced by TUnicode::FindWordBoundaries(), GetCaseConverted(), and TestFindNextWordOrSentenceBoundary().
{
if (size_t(dest.Len()) != srcCount + 1) dest.Gen(TVecIdx(srcCount + 1));
dest.PutAll(false);
size_t position = srcIdx;
dest[TVecIdx(position - srcIdx)] = true;
while (position < srcIdx + srcCount)
{
size_t oldPos = position;
FindNextWordBoundary(src, srcIdx, srcCount, position);
Assert(oldPos < position); Assert(position <= srcIdx + srcCount);
dest[TVecIdx(position - srcIdx)] = true;
}
Assert(dest[TVecIdx(srcCount)]);
}

| static TStr TUniChDb::GetAuxiliaryDir | ( | ) | [inline, static] |
Definition at line 1304 of file unicode.h.
Referenced by InitWordAndSentenceBoundaryFlags(), and TestFindNextWordOrSentenceBoundary().
{ return "auxiliary"; }

| static TStr TUniChDb::GetBinFn | ( | ) | [inline, static] |
| void TUniChDb::GetCaseConverted | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest, | ||
| const TCaseConversion | how, | ||
| const bool | turkic, | ||
| const bool | lithuanian | ||
| ) | const |
Definition at line 2811 of file unicode.h.
References TVec< TVal, TSizeTy >::Add(), TUniCaseFolding::AppendVector(), Assert, TUniChInfo::ccAbove, ccLower, TUniChInfo::ccStarter, ccTitle, ccUpper, TVec< TVal, TSizeTy >::Clr(), FindNextWordBoundary(), FindWordBoundaries(), GetCombiningClass(), THash< TKey, TDat, THashFunc >::GetKeyId(), h, IAssert, TUniChInfo::simpleLowerCaseMapping, TUniChInfo::simpleTitleCaseMapping, TUniChInfo::simpleUpperCaseMapping, specialCasingLower, specialCasingTitle, and specialCasingUpper.
Referenced by GetLowerCase(), GetTitleCase(), GetUpperCase(), and TestCaseConversion().
{
const TIntIntVH &specials = (how == ccUpper ? specialCasingUpper : how == ccLower ? specialCasingLower : how == ccTitle ? specialCasingTitle : *((TIntIntVH *) 0));
if (clrDest) dest.Clr();
enum {
GreekCapitalLetterSigma = 0x3a3,
GreekSmallLetterSigma = 0x3c3,
GreekSmallLetterFinalSigma = 0x3c2,
LatinCapitalLetterI = 0x49,
LatinCapitalLetterJ = 0x4a,
LatinCapitalLetterIWithOgonek = 0x12e,
LatinCapitalLetterIWithGrave = 0xcc,
LatinCapitalLetterIWithAcute = 0xcd,
LatinCapitalLetterIWithTilde = 0x128,
LatinCapitalLetterIWithDotAbove = 0x130,
LatinSmallLetterI = 0x69,
CombiningDotAbove = 0x307
};
//
bool seenCased = false, seenTwoCased = false; int cpFirstCased = -1;
size_t nextWordBoundary = srcIdx;
TBoolV wordBoundaries; bool wbsKnown = false;
for (const size_t origSrcIdx = srcIdx, srcEnd = srcIdx + srcCount; srcIdx < srcEnd; )
{
int cp = src[TVecIdx(srcIdx)]; srcIdx++;
//if (turkic && cp == 0x130 && how == ccLower) printf("!");
// For conversion to titlecase, the first cased character of each word
// must be converted to titlecase; everything else must be converted
// to lowercase.
TUniChDb::TCaseConversion howHere;
if (how != ccTitle) howHere = how;
else {
if (srcIdx - 1 == nextWordBoundary) { // A word starts/ends here.
seenCased = false; seenTwoCased = false; cpFirstCased = -1;
size_t next = nextWordBoundary; FindNextWordBoundary(src, origSrcIdx, srcCount, next);
IAssert(next > nextWordBoundary); nextWordBoundary = next; }
bool isCased = IsCased(cp);
if (isCased && ! seenCased) { howHere = ccTitle; seenCased = true; cpFirstCased = cp; }
else { howHere = ccLower;
if (isCased && seenCased) seenTwoCased = true; }
}
// First, process the conditional mappings from SpecialCasing.txt.
// These will be processed in code -- they were ignored while
// we were reading SpecialCasing.txt itself.
if (cp == GreekCapitalLetterSigma && howHere == ccLower)
{
// SpecialCasing.txt mentions the 'FinalSigma' condition, but sec. 3.13 of
// the standard doesn't define it. We'll use FinalCased instead.
// FinalCased: within the closest word boundaries containing C,
// there is a cased letter before C, and there is no cased letter after C.
//size_t nextBoundary = srcIdx - 1; FindNextWordBoundary(src, srcIdx, srcCount, nextBoundary);
if (! wbsKnown) { FindWordBoundaries(src, origSrcIdx, srcCount, wordBoundaries); wbsKnown = true; }
size_t srcIdx2 = srcIdx; bool casedAfter = false;
if (how == ccTitle)
printf("!");
//while (srcIdx2 < nextBoundary)
while (! wordBoundaries[TVecIdx(srcIdx2 - origSrcIdx)])
{
int cp2 = src[TVecIdx(srcIdx2)]; srcIdx2++;
if (IsCased(cp2)) { casedAfter = true; break; }
}
if (! casedAfter)
{
//size_t prevBoundary = srcIdx - 1;
//FindPreviousWordBoundary(src, srcIdx, srcCount, prevBoundary);
srcIdx2 = srcIdx - 1; bool casedBefore = false;
//while (prevBoundary < srcIdx2)
while (! wordBoundaries[TVecIdx(srcIdx2 - origSrcIdx)])
{
--srcIdx2; int cp2 = src[TVecIdx(srcIdx2)];
if (IsCased(cp2)) { casedBefore = true; break; }
}
if (casedBefore) {
// Now we have a FinalCased character.
dest.Add(GreekSmallLetterFinalSigma); Assert(howHere == ccLower); continue; }
}
// If we got here, add a non-final sigma.
dest.Add(GreekSmallLetterSigma); continue;
}
else if (lithuanian)
{
if (howHere == ccLower)
{
if (cp == LatinCapitalLetterI || cp == LatinCapitalLetterJ || cp == LatinCapitalLetterIWithOgonek)
{
bool moreAbove = false;
for (size_t srcIdx2 = srcIdx; srcIdx2 < srcEnd; )
{
const int cp2 = src[TVecIdx(srcIdx2)]; srcIdx2++;
const int cc2 = GetCombiningClass(cp2);
if (cc2 == TUniChInfo::ccStarter) break;
if (cc2 == TUniChInfo::ccAbove) { moreAbove = true; break; }
}
if (moreAbove)
{
if (cp == LatinCapitalLetterI) { dest.Add(0x69); dest.Add(0x307); continue; }
if (cp == LatinCapitalLetterJ) { dest.Add(0x6a); dest.Add(0x307); continue; }
if (cp == LatinCapitalLetterIWithOgonek) { dest.Add(0x12f); dest.Add(0x307); continue; }
}
}
else if (cp == LatinCapitalLetterIWithGrave) { dest.Add(0x69); dest.Add(0x307); dest.Add(0x300); continue; }
else if (cp == LatinCapitalLetterIWithAcute) { dest.Add(0x69); dest.Add(0x307); dest.Add(0x301); continue; }
else if (cp == LatinCapitalLetterIWithTilde) { dest.Add(0x69); dest.Add(0x307); dest.Add(0x303); continue; }
}
if (cp == CombiningDotAbove)
{
// Lithuanian, howHere != ccLower.
// AfterSoftDotted := the last preceding character with a combining class
// of zero before C was Soft_Dotted, and there is no intervening combining
// character class 230 (ABOVE).
bool afterSoftDotted = false;
size_t srcIdx2 = srcIdx - 1; // now srcIdx2 is the index from which we got 'cp'
while (origSrcIdx < srcIdx2)
{
--srcIdx2; int cp2 = src[TVecIdx(srcIdx2)];
int cc2 = GetCombiningClass(cp2);
if (cc2 == TUniChInfo::ccAbove) break;
if (cc2 == TUniChInfo::ccStarter) {
afterSoftDotted = IsSoftDotted(cp2); break; }
}
if (afterSoftDotted)
{
Assert(lithuanian);
// Remove DOT ABOVE after "i" with upper or titlecase.
// - Note: but this must only be done if that "i" was actually placed into uppercase (if how == ccTitle,
// the "i" may have been kept lowercase and thus we shouldn't remove the dot).
if (how == ccLower) { dest.Add(0x307); continue; }
if (how == ccUpper) continue;
Assert(how == ccTitle);
Assert(howHere == ccLower); // because CombiningDotAbove is not a cased character
if (seenCased && ! seenTwoCased) continue; // The "i" has been placed into uppercase; thus, remove the dot.
dest.Add(0x307); continue;
}
}
}
else if (turkic) // language code 'tr' (Turkish) and 'az' (Azeri)
{
// I and i-dotless; I-dot and i are case pairs in Turkish and Azeri
// The following rules handle those cases.
if (cp == LatinCapitalLetterIWithDotAbove) {
dest.Add(howHere == ccLower ? 0x69 : 0x130); continue; }
// When lowercasing, remove dot_above in the sequence I + dot_above,
// which will turn into i. This matches the behavior of the
// canonically equivalent I-dot_above.
else if (cp == CombiningDotAbove)
{
// AfterI: the last preceding base character was an uppercase I,
// and there is no intervening combining character class 230 (ABOVE).
bool afterI = false;
size_t srcIdx2 = srcIdx - 1; // now srcIdx2 is the index from which we got 'cp'
while (origSrcIdx < srcIdx2)
{
--srcIdx2; int cp2 = src[TVecIdx(srcIdx2)];
if (cp2 == LatinCapitalLetterI) { afterI = true; break; }
int cc2 = GetCombiningClass(cp2);
if (cc2 == TUniChInfo::ccAbove || cc2 == TUniChInfo::ccStarter) break;
}
if (afterI) {
if (how == ccTitle && seenCased && ! seenTwoCased) {
// Sec. 3.13 defines title-casing in an unusual way: find the first cased character in each word;
// if found, map it to titlecase; otherwise, map all characters in that word to lowercase.
// This suggests that if a cased character is found, others in that word should be left alone.
// This seems unusual; we map all other characters to lowercase instead.
// But this leads to problems with e.g. I followed by dot-above (U+0307): since the dot-above
// is not the first cased character (it isn't even cased), we attempt to set it to lowercase;
// but since afterI is also true here, this would mean deleting it. Thus our titlecased
// form of "I followed by dot-above" would be just "I", which is clearly wrong.
// So we treat this as a special case here.
IAssert(cpFirstCased == LatinCapitalLetterI);
dest.Add(0x307); continue; }
if (howHere != ccLower) dest.Add(0x307);
continue; }
}
// When lowercasing, unless an I is before a dot_above,
// it turns into a dotless i.
else if (cp == LatinCapitalLetterI)
{
// BeforeDot: C is followed by U+0307 (combining dot above).
// Any sequence of characters with a combining class that is
// neither 0 nor 230 may intervene between the current character
// and the combining dot above.
bool beforeDot = false;
for (size_t srcIdx2 = srcIdx; srcIdx2 < srcEnd; )
{
const int cp2 = src[TVecIdx(srcIdx2)]; srcIdx2++;
if (cp2 == 0x307) { beforeDot = true; break; }
const int cc2 = GetCombiningClass(cp2);
if (cc2 == TUniChInfo::ccStarter || cc2 == TUniChInfo::ccAbove) break;
}
if (! beforeDot) {
dest.Add(howHere == ccLower ? 0x131 : 0x49); continue; }
}
// When uppercasing, i turns into a dotted capital I.
else if (cp == LatinSmallLetterI)
{
dest.Add(howHere == ccLower ? 0x69 : 0x130); continue;
}
}
// Try to use the unconditional mappings.
const TIntIntVH &specHere = (
howHere == how ? specials :
howHere == ccLower ? specialCasingLower :
howHere == ccTitle ? specialCasingTitle :
howHere == ccUpper ? specialCasingUpper : *((TIntIntVH *) 0));
int i = specHere.GetKeyId(cp);
if (i >= 0) { TUniCaseFolding::AppendVector(specHere[i], dest); continue; }
// Try to use the simple (one-character) mappings.
i = h.GetKeyId(cp);
if (i >= 0) {
const TUniChInfo &ci = h[i];
int cpNew = (
howHere == ccLower ? ci.simpleLowerCaseMapping :
howHere == ccUpper ? ci.simpleUpperCaseMapping :
ci.simpleTitleCaseMapping);
if (cpNew < 0) cpNew = cp;
dest.Add(cpNew); continue; }
// As a final resort, leave 'cp' unchanged.
dest.Add(cp);
}
}

| void TUniChDb::GetCaseFolded | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest, | ||
| const bool | full, | ||
| const bool | turkic = false |
||
| ) | const [inline] |
Definition at line 1629 of file unicode.h.
References caseFolding, and TUniCaseFolding::Fold().
Referenced by GetCaseFolded(), and TUnicode::GetCaseFolded().
{ caseFolding.Fold(src, srcIdx, srcCount, dest, clrDest, full, turkic); }


| void TUniChDb::GetCaseFolded | ( | const TSrcVec & | src, |
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true, |
||
| const bool | full = true, |
||
| const bool | turkic = false |
||
| ) | const [inline] |
Definition at line 1632 of file unicode.h.
References GetCaseFolded().
{
GetCaseFolded(src, 0, src.Len(), dest, clrDest, full, turkic); }

| static TStr TUniChDb::GetCaseFoldingFn | ( | ) | [inline, static] |
| TUniChCategory TUniChDb::GetCat | ( | const int | cp | ) | const [inline] |
Definition at line 1353 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
Referenced by TUnicode::___UniFwd2(), and CanSentenceEndHere().


| const char* TUniChDb::GetCharName | ( | const int | cp | ) | const [inline] |
Definition at line 1331 of file unicode.h.
References charNames, TStrPool::GetCStr(), THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
Referenced by TUnicode::GetCharName(), and GetCharNameS().
{ int i = h.GetKeyId(cp); if (i < 0) return 0; int ofs = h[i].nameOffset; return ofs < 0 ? 0 : charNames.GetCStr(ofs); }


| TStr TUniChDb::GetCharNameS | ( | const int | cp | ) | const [inline] |
Definition at line 1332 of file unicode.h.
References GetCharName().
Referenced by TUnicode::GetCharNameS(), and PrintCharNames().
{
// ToDo: Add special processing for precomposed Hangul syllables (UAX #15, sec. 16).
const char *p = GetCharName(cp); if (p) return p;
char buf[20]; sprintf(buf, "U+%04x", cp); return TStr(buf); }


| int TUniChDb::GetCombiningClass | ( | const int | cp | ) | const [inline] |
Definition at line 1399 of file unicode.h.
References TUniChInfo::ccStarter, THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
Referenced by Compose(), Decompose(), ExtractStarters(), and GetCaseConverted().
{ int i = h.GetKeyId(cp); if (i < 0) return TUniChInfo::ccStarter; else return h[i].combClass; }


| static TStr TUniChDb::GetCompositionExclusionsFn | ( | ) | [inline, static] |
| static TStr TUniChDb::GetDerivedCorePropsFn | ( | ) | [inline, static] |
Definition at line 1301 of file unicode.h.
Referenced by InitDerivedCoreProperties().
{ return "DerivedCoreProperties.txt"; }

| static TStr TUniChDb::GetLineBreakFn | ( | ) | [inline, static] |
Definition at line 1302 of file unicode.h.
Referenced by InitLineBreaks().
{ return "LineBreak.txt"; }

| void TUniChDb::GetLowerCase | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true, |
||
| const bool | turkic = false, |
||
| const bool | lithuanian = false |
||
| ) | const [inline] |
Definition at line 1590 of file unicode.h.
References ccLower, and GetCaseConverted().
Referenced by TUnicode::GetLowerCase().
{ GetCaseConverted(src, srcIdx, srcCount, dest, clrDest, ccLower, turkic, lithuanian); }


| void TUniChDb::GetLowerCase | ( | const TSrcVec & | src, |
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true, |
||
| const bool | turkic = false, |
||
| const bool | lithuanian = false |
||
| ) | const [inline] |
Definition at line 1593 of file unicode.h.
References GetLowerCase().
Referenced by GetLowerCase().
{ GetLowerCase(src, 0, src.Len(), dest, clrDest, turkic, lithuanian); }


| static TStr TUniChDb::GetNormalizationTestFn | ( | ) | [inline, static] |
Definition at line 1309 of file unicode.h.
Referenced by TestComposition().
{ return "NormalizationTest.txt"; }

| static TStr TUniChDb::GetPropListFn | ( | ) | [inline, static] |
Definition at line 1303 of file unicode.h.
Referenced by InitPropList().
{ return "PropList.txt"; }

| int TUniChDb::GetSbFlags | ( | const int | cp | ) | const [inline] |
Definition at line 1359 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
Referenced by CanSentenceEndHere(), FindNextSentenceBoundary(), and TestFindNextWordOrSentenceBoundary().


| int TUniChDb::GetScript | ( | const TUniChInfo & | ci | ) | const [inline] |
Definition at line 1323 of file unicode.h.
References TUniChInfo::script, and scriptUnknown.
Referenced by TUStr::GetChScriptId().
{ int s = ci.script; if (s < 0) s = scriptUnknown; return s; }
| int TUniChDb::GetScript | ( | const int | cp | ) | const [inline] |
Definition at line 1324 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), GetScript(), h, and scriptUnknown.
Referenced by GetScript().
{ int i = h.GetKeyId(cp); if (i < 0) return scriptUnknown; else return GetScript(h[i]); }

| int TUniChDb::GetScriptByName | ( | const TStr & | scriptName | ) | const [inline] |
Definition at line 1322 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and scripts.
Referenced by TUStr::GetScriptId(), InitAfterLoad(), InitWordAndSentenceBoundaryFlags(), and LoadTxt().


| const TStr& TUniChDb::GetScriptName | ( | const int | scriptId | ) | const [inline] |
Definition at line 1321 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKey(), and scripts.
Referenced by TUStr::GetScriptNm(), and TestWbFindNonIgnored().


| static TStr TUniChDb::GetScriptNameHiragana | ( | ) | [inline, static] |
Definition at line 1319 of file unicode.h.
Referenced by InitWordAndSentenceBoundaryFlags().
{ return "Hiragana"; }

| static TStr TUniChDb::GetScriptNameKatakana | ( | ) | [inline, static] |
Definition at line 1318 of file unicode.h.
Referenced by InitWordAndSentenceBoundaryFlags().
{ return "Katakana"; }

| static TStr TUniChDb::GetScriptNameUnknown | ( | ) | [inline, static] |
Definition at line 1317 of file unicode.h.
Referenced by InitAfterLoad(), InitScripts(), and LoadTxt().
{ return "Unknown"; }

| static TStr TUniChDb::GetScriptsFn | ( | ) | [inline, static] |
Definition at line 1300 of file unicode.h.
Referenced by InitScripts().
{ return "Scripts.txt"; }

| static TStr TUniChDb::GetSentenceBreakPropertyFn | ( | ) | [inline, static] |
Definition at line 1308 of file unicode.h.
Referenced by InitWordAndSentenceBoundaryFlags().
{ return "SentenceBreakProperty.txt"; }

| static TStr TUniChDb::GetSentenceBreakTestFn | ( | ) | [inline, static] |
Definition at line 1307 of file unicode.h.
Referenced by TestFindNextWordOrSentenceBoundary().
{ return "SentenceBreakTest.txt"; }

| void TUniChDb::GetSimpleCaseConverted | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest, | ||
| const TCaseConversion | how | ||
| ) | const |
Definition at line 3036 of file unicode.h.
References TVec< TVal, TSizeTy >::Add(), ccLower, ccTitle, ccUpper, TVec< TVal, TSizeTy >::Clr(), FindNextWordBoundary(), THash< TKey, TDat, THashFunc >::GetKeyId(), h, IAssert, TUniChInfo::simpleLowerCaseMapping, TUniChInfo::simpleTitleCaseMapping, and TUniChInfo::simpleUpperCaseMapping.
Referenced by GetSimpleLowerCase(), GetSimpleTitleCase(), and GetSimpleUpperCase().
{
if (clrDest) dest.Clr();
bool seenCased = false; size_t nextWordBoundary = srcIdx;
for (const size_t origSrcIdx = srcIdx, srcEnd = srcIdx + srcCount; srcIdx < srcEnd; )
{
const int cp = src[TVecIdx(srcIdx)]; srcIdx++;
int i = h.GetKeyId(cp); if (i < 0) { dest.Add(cp); continue; }
const TUniChInfo &ci = h[i];
// With titlecasing, the first cased character of each word must be put into titlecase,
// all others into lowercase. This is what the howHere variable is for.
TUniChDb::TCaseConversion howHere;
if (how != ccTitle) howHere = how;
else {
if (srcIdx - 1 == nextWordBoundary) { // A word starts/ends here.
seenCased = false;
size_t next = nextWordBoundary; FindNextWordBoundary(src, origSrcIdx, srcCount, next);
IAssert(next > nextWordBoundary); nextWordBoundary = next; }
bool isCased = IsCased(cp);
if (isCased && ! seenCased) { howHere = ccTitle; seenCased = true; }
else howHere = ccLower;
}
int cpNew = (howHere == ccTitle ? ci.simpleTitleCaseMapping : howHere == ccUpper ? ci.simpleUpperCaseMapping : ci.simpleLowerCaseMapping);
if (cpNew < 0) cpNew = cp;
dest.Add(cpNew);
}
}


| void TUniChDb::GetSimpleLowerCase | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true |
||
| ) | const [inline] |
Definition at line 1601 of file unicode.h.
References ccLower, and GetSimpleCaseConverted().
Referenced by TUnicode::GetSimpleLowerCase().
{ GetSimpleCaseConverted(src, srcIdx, srcCount, dest, clrDest, ccLower); }

| void TUniChDb::GetSimpleLowerCase | ( | const TSrcVec & | src, |
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true |
||
| ) | const [inline] |
Definition at line 1604 of file unicode.h.
References GetSimpleLowerCase().
Referenced by GetSimpleLowerCase().
{ GetSimpleLowerCase(src, 0, src.Len(), dest, clrDest); }


| void TUniChDb::GetSimpleTitleCase | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true |
||
| ) | const [inline] |
Definition at line 1603 of file unicode.h.
References ccTitle, and GetSimpleCaseConverted().
Referenced by TUnicode::GetSimpleTitleCase().
{ GetSimpleCaseConverted(src, srcIdx, srcCount, dest, clrDest, ccTitle); }


| void TUniChDb::GetSimpleTitleCase | ( | const TSrcVec & | src, |
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true |
||
| ) | const [inline] |
Definition at line 1606 of file unicode.h.
References GetSimpleTitleCase().
Referenced by GetSimpleTitleCase().
{ GetSimpleTitleCase(src, 0, src.Len(), dest, clrDest); }


| void TUniChDb::GetSimpleUpperCase | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true |
||
| ) | const [inline] |
Definition at line 1602 of file unicode.h.
References ccUpper, and GetSimpleCaseConverted().
Referenced by TUnicode::GetSimpleUpperCase().
{ GetSimpleCaseConverted(src, srcIdx, srcCount, dest, clrDest, ccUpper); }


| void TUniChDb::GetSimpleUpperCase | ( | const TSrcVec & | src, |
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true |
||
| ) | const [inline] |
Definition at line 1605 of file unicode.h.
References GetSimpleUpperCase().
Referenced by GetSimpleUpperCase().
{ GetSimpleUpperCase(src, 0, src.Len(), dest, clrDest); }


| static TStr TUniChDb::GetSpecialCasingFn | ( | ) | [inline, static] |
Definition at line 1297 of file unicode.h.
Referenced by InitSpecialCasing().
{ return "SpecialCasing.txt"; }

| TUniChSubCategory TUniChDb::GetSubCat | ( | const int | cp | ) | const [inline] |
Definition at line 1354 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
Referenced by TUnicode::GetSubCat().


| void TUniChDb::GetTitleCase | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true, |
||
| const bool | turkic = false, |
||
| const bool | lithuanian = false |
||
| ) | const [inline] |
Definition at line 1592 of file unicode.h.
References ccTitle, and GetCaseConverted().
Referenced by TUnicode::GetTitleCase().
{ GetCaseConverted(src, srcIdx, srcCount, dest, clrDest, ccTitle, turkic, lithuanian); }


| void TUniChDb::GetTitleCase | ( | const TSrcVec & | src, |
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true, |
||
| const bool | turkic = false, |
||
| const bool | lithuanian = false |
||
| ) | const [inline] |
Definition at line 1595 of file unicode.h.
References GetTitleCase().
Referenced by GetTitleCase().
{ GetTitleCase(src, 0, src.Len(), dest, clrDest, turkic, lithuanian); }


| static TStr TUniChDb::GetUnicodeDataFn | ( | ) | [inline, static] |
| void TUniChDb::GetUpperCase | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true, |
||
| const bool | turkic = false, |
||
| const bool | lithuanian = false |
||
| ) | const [inline] |
Definition at line 1591 of file unicode.h.
References ccUpper, and GetCaseConverted().
Referenced by TUnicode::GetUpperCase().
{ GetCaseConverted(src, srcIdx, srcCount, dest, clrDest, ccUpper, turkic, lithuanian); }


| void TUniChDb::GetUpperCase | ( | const TSrcVec & | src, |
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest = true, |
||
| const bool | turkic = false, |
||
| const bool | lithuanian = false |
||
| ) | const [inline] |
Definition at line 1594 of file unicode.h.
References GetUpperCase().
Referenced by GetUpperCase().
{ GetUpperCase(src, 0, src.Len(), dest, clrDest, turkic, lithuanian); }


| int TUniChDb::GetWbFlags | ( | const int | cp | ) | const [inline] |
Definition at line 1357 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
Referenced by FindNextWordBoundary(), and TestFindNextWordOrSentenceBoundary().

| static TStr TUniChDb::GetWordBreakPropertyFn | ( | ) | [inline, static] |
Definition at line 1306 of file unicode.h.
Referenced by InitWordAndSentenceBoundaryFlags().
{ return "WordBreakProperty.txt"; }

| static TStr TUniChDb::GetWordBreakTestFn | ( | ) | [inline, static] |
Definition at line 1305 of file unicode.h.
Referenced by TestFindNextWordOrSentenceBoundary().
{ return "WordBreakTest.txt"; }

| void TUniChDb::InitAfterLoad | ( | ) | [protected] |
Definition at line 1368 of file unicode.cpp.
References GetScriptByName(), GetScriptNameUnknown(), IAssert, and scriptUnknown.
Referenced by Load().
{
scriptUnknown = GetScriptByName(GetScriptNameUnknown()); IAssert(scriptUnknown >= 0);
}


| void TUniChDb::InitDerivedCoreProperties | ( | const TStr & | basePath | ) | [protected] |
Definition at line 1007 of file unicode.cpp.
References THash< TKey, TDat, THashFunc >::AddKey(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), TStr::CStr(), FailR, GetDerivedCorePropsFn(), THash< TKey, TDat, THashFunc >::GetKeyId(), TUniChDb::TUcdFileReader::GetNextLine(), h, IAssert, TUniChInfo::IsDcpFlag(), TVec< TVal, TSizeTy >::Len(), TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePointRange(), TUniChDb::TSubcatHelper::ProcessComment(), TUniChDb::TSubcatHelper::SetCat(), TUniChInfo::SetDcpFlag(), TUniChDb::TSubcatHelper::TestCat(), ucfCompatibilityDecomposition, ucfDcpAlphabetic, ucfDcpDefaultIgnorableCodePoint, ucfDcpGraphemeBase, ucfDcpGraphemeExtend, ucfDcpIdContinue, ucfDcpIdStart, ucfDcpLowercase, ucfDcpMath, ucfDcpUppercase, ucfDcpXidContinue, and ucfDcpXidStart.
Referenced by LoadTxt().
{
TUcdFileReader reader; TStrV fields; int nCps = 0, nLines = 0;
reader.Open(CombinePath(basePath, GetDerivedCorePropsFn()));
TSubcatHelper helper(*this);
while (reader.GetNextLine(fields))
{
IAssert(fields.Len() == 2);
int from, to; reader.ParseCodePointRange(fields[0], from, to);
TStr s = fields[1];
TUniChFlags flag = ucfCompatibilityDecomposition;
if (s == "Math") flag = ucfDcpMath;
else if (s == "Alphabetic") flag = ucfDcpAlphabetic;
else if (s == "Lowercase") flag = ucfDcpLowercase;
else if (s == "Uppercase") flag = ucfDcpUppercase;
else if (s == "ID_Start") flag = ucfDcpIdStart;
else if (s == "ID_Continue") flag = ucfDcpIdContinue;
else if (s == "XID_Start") flag = ucfDcpXidStart;
else if (s == "XID_Continue") flag = ucfDcpXidContinue;
else if (s == "Default_Ignorable_Code_Point") flag = ucfDcpDefaultIgnorableCodePoint;
else if (s == "Grapheme_Extend") flag = ucfDcpGraphemeExtend;
else if (s == "Grapheme_Base") flag = ucfDcpGraphemeBase;
else if (s == "Grapheme_Link") continue; // this flag is deprecated; test for combClass == Virama instead
else FailR(s.CStr());
// If we add new codepoints to the hash table, we should also set their category.
// This is supposed to be provided in the comment, e.g. "# Cf SOFT HYPHEN".
helper.ProcessComment(reader);
//
for (int cp = from; cp <= to; cp++) {
int i = h.GetKeyId(cp); if (i < 0) { i = h.AddKey(cp); helper.SetCat(cp); }
helper.TestCat(cp);
TUniChInfo &ci = h[i]; IAssert(! ci.IsDcpFlag(flag));
ci.SetDcpFlag(flag); nCps++; }
nLines++;
}
reader.Close();
printf("TUniChDb::InitDerivedCoreProperties: %d lines, %d code points.\n", nLines, nCps);
}


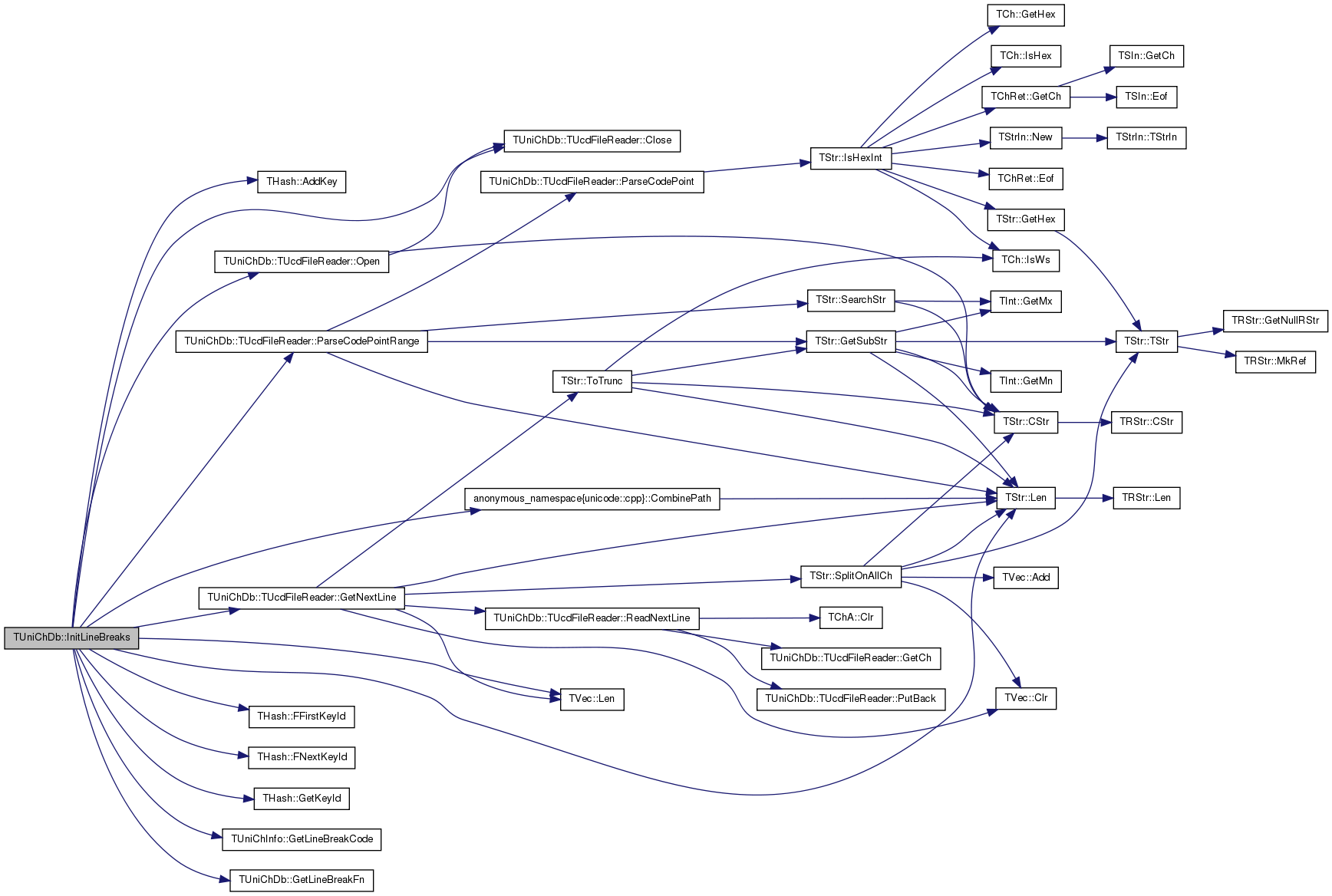
| void TUniChDb::InitLineBreaks | ( | const TStr & | basePath | ) | [protected] |
Definition at line 1046 of file unicode.cpp.
References THash< TKey, TDat, THashFunc >::AddKey(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), THash< TKey, TDat, THashFunc >::FFirstKeyId(), THash< TKey, TDat, THashFunc >::FNextKeyId(), THash< TKey, TDat, THashFunc >::GetKeyId(), TUniChInfo::GetLineBreakCode(), GetLineBreakFn(), TUniChDb::TUcdFileReader::GetNextLine(), h, IAssert, TStr::Len(), TVec< TVal, TSizeTy >::Len(), TUniChInfo::LineBreak_Unknown, TUniChDb::TUcdFileReader::Open(), and TUniChDb::TUcdFileReader::ParseCodePointRange().
Referenced by LoadTxt().
{
// Clear old linebreak values.
ushort xx = TUniChInfo::LineBreak_Unknown;
for (int i = h.FFirstKeyId(); h.FNextKeyId(i); ) h[i].lineBreak = xx;
// Read LineBreak.txt.
TUcdFileReader reader; TStrV fields;
reader.Open(CombinePath(basePath, GetLineBreakFn()));
int nLines = 0, nCps = 0;
while (reader.GetNextLine(fields))
{
IAssert(fields.Len() == 2);
int from, to; reader.ParseCodePointRange(fields[0], from, to);
TStr s = fields[1]; IAssert(s.Len() == 2);
ushort us = TUniChInfo::GetLineBreakCode(s[0], s[1]);
if (us == xx) continue;
for (int cp = from; cp <= to; cp++) {
int i = h.GetKeyId(cp); if (i < 0) { i = h.AddKey(cp);
printf("TUniChDb::InitLineBreaks: warning, adding codepoint %d, its category will remain unknown.\n", cp); }
IAssert(h[i].lineBreak == xx);
h[i].lineBreak = us; nCps++; }
nLines++;
}
reader.Close();
printf("TUniChDb::InitLineBreaks: %d lines, %d codepoints processed (excluding \'xx\' values).\n", nLines, nCps);
}

| void TUniChDb::InitPropList | ( | const TStr & | basePath | ) | [protected] |
Definition at line 950 of file unicode.cpp.
References THash< TKey, TDat, THashFunc >::AddKey(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), TStr::CStr(), FailR, THash< TKey, TDat, THashFunc >::GetKeyId(), TUniChDb::TUcdFileReader::GetNextLine(), GetPropListFn(), h, IAssert, TUniChInfo::IsProperty(), TUniChInfo::IsPropertyX(), TVec< TVal, TSizeTy >::Len(), TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePointRange(), TUniChDb::TSubcatHelper::ProcessComment(), TUniChDb::TSubcatHelper::SetCat(), TUniChInfo::SetProperty(), TUniChInfo::SetPropertyX(), TUniChDb::TSubcatHelper::TestCat(), ucfPrAsciiHexDigit, ucfPrBidiControl, ucfPrDash, ucfPrDeprecated, ucfPrDiacritic, ucfPrExtender, ucfPrHexDigit, ucfPrHyphen, ucfPrIdeographic, ucfPrJoinControl, ucfPrLogicalOrderException, ucfPrNoncharacterCodePoint, ucfPrPatternSyntax, ucfPrPatternWhiteSpace, ucfPrQuotationMark, ucfPrSoftDotted, ucfPrSTerm, ucfPrTerminalPunctuation, ucfPrVariationSelector, ucfPrWhiteSpace, ucfPxIdsBinaryOperator, ucfPxIdsTrinaryOperator, ucfPxOtherAlphabetic, ucfPxOtherDefaultIgnorableCodePoint, ucfPxOtherGraphemeExtend, ucfPxOtherIdContinue, ucfPxOtherIdStart, ucfPxOtherLowercase, ucfPxOtherMath, ucfPxOtherUppercase, ucfPxRadical, and ucfPxUnifiedIdeograph.
Referenced by LoadTxt().
{
TUcdFileReader reader; TStrV fields; int nCps = 0, nLines = 0;
reader.Open(CombinePath(basePath, GetPropListFn()));
TSubcatHelper helper(*this);
while (reader.GetNextLine(fields))
{
IAssert(fields.Len() == 2);
int from, to; reader.ParseCodePointRange(fields[0], from, to);
TStr s = fields[1];
TUniChProperties prop = TUniChProperties(0); TUniChPropertiesX propx = TUniChPropertiesX(0);
if (s == "White_Space") prop = ucfPrWhiteSpace;
else if (s == "Bidi_Control") prop = ucfPrBidiControl;
else if (s == "Join_Control") prop = ucfPrJoinControl;
else if (s == "Dash") prop = ucfPrDash;
else if (s == "Hyphen") prop = ucfPrHyphen;
else if (s == "Quotation_Mark") prop = ucfPrQuotationMark;
else if (s == "Terminal_Punctuation") prop = ucfPrTerminalPunctuation;
else if (s == "Other_Math") propx = ucfPxOtherMath;
else if (s == "Hex_Digit") prop = ucfPrHexDigit;
else if (s == "ASCII_Hex_Digit") prop = ucfPrAsciiHexDigit;
else if (s == "Other_Alphabetic") propx = ucfPxOtherAlphabetic;
else if (s == "Ideographic") prop = ucfPrIdeographic;
else if (s == "Diacritic") prop = ucfPrDiacritic;
else if (s == "Extender") prop = ucfPrExtender;
else if (s == "Other_Lowercase") propx = ucfPxOtherLowercase;
else if (s == "Other_Uppercase") propx = ucfPxOtherUppercase;
else if (s == "Noncharacter_Code_Point") prop = ucfPrNoncharacterCodePoint;
else if (s == "Other_Grapheme_Extend") propx = ucfPxOtherGraphemeExtend;
else if (s == "IDS_Binary_Operator") propx = ucfPxIdsBinaryOperator;
else if (s == "IDS_Trinary_Operator") propx = ucfPxIdsTrinaryOperator;
else if (s == "Radical") propx = ucfPxRadical;
else if (s == "Unified_Ideograph") propx = ucfPxUnifiedIdeograph;
else if (s == "Other_Default_Ignorable_Code_Point") propx = ucfPxOtherDefaultIgnorableCodePoint;
else if (s == "Deprecated") prop = ucfPrDeprecated;
else if (s == "Soft_Dotted") prop = ucfPrSoftDotted;
else if (s == "Logical_Order_Exception") prop = ucfPrLogicalOrderException;
else if (s == "Other_ID_Start") propx = ucfPxOtherIdStart;
else if (s == "Other_ID_Continue") propx = ucfPxOtherIdContinue;
else if (s == "STerm") prop = ucfPrSTerm;
else if (s == "Variation_Selector") prop = ucfPrVariationSelector;
else if (s == "Pattern_White_Space") prop = ucfPrPatternWhiteSpace;
else if (s == "Pattern_Syntax") prop = ucfPrPatternSyntax;
else FailR(s.CStr());
helper.ProcessComment(reader);
for (int cp = from; cp <= to; cp++) {
int i = h.GetKeyId(cp); if (i < 0) { i = h.AddKey(cp); helper.SetCat(cp); }
TUniChInfo &ci = h[i]; helper.TestCat(cp);
if (prop) { IAssert(! ci.IsProperty(prop)); ci.SetProperty(prop); }
if (propx) { IAssert(! ci.IsPropertyX(propx)); ci.SetPropertyX(propx); }
nCps++; }
nLines++;
}
reader.Close();
printf("TUniChDb::InitPropList: %d lines, %d code points.\n", nLines, nCps);
}


| void TUniChDb::InitScripts | ( | const TStr & | basePath | ) | [protected] |
Definition at line 1073 of file unicode.cpp.
References THash< TKey, TDat, THashFunc >::AddDat(), THash< TKey, TDat, THashFunc >::AddKey(), AlwaysFalse(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), TStr::CStr(), THash< TKey, TDat, THashFunc >::FFirstKeyId(), THash< TKey, TDat, THashFunc >::FNextKeyId(), THash< TKey, TDat, THashFunc >::GetKey(), THash< TKey, TDat, THashFunc >::GetKeyId(), TUniChDb::TUcdFileReader::GetNextLine(), GetScriptNameUnknown(), GetScriptsFn(), h, IAssert, THash< TKey, TDat, THashFunc >::Len(), TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePointRange(), TUniChDb::TSubcatHelper::ProcessComment(), TUniChInfo::script, scripts, TUniChDb::TSubcatHelper::SetCat(), and TUniChDb::TSubcatHelper::TestCat().
Referenced by LoadTxt().
{
TUcdFileReader reader; TStrV fields;
reader.Open(CombinePath(basePath, GetScriptsFn()));
TSubcatHelper helper(*this);
while (reader.GetNextLine(fields))
{
int from, to; reader.ParseCodePointRange(fields[0], from, to);
TStr scriptName = fields[1];
int scriptNo = scripts.GetKeyId(scriptName);
if (scriptNo < 0) { scriptNo = scripts.AddKey(scriptName); scripts[scriptNo] = 0; }
IAssert(scriptNo >= 0 && scriptNo < SCHAR_MAX); // because TUniChInfo.script is a signed char
scripts[scriptNo] += 1;
helper.ProcessComment(reader);
for (int cp = from; cp <= to; cp++) {
int i = h.GetKeyId(cp); if (i < 0) { i = h.AddKey(cp); helper.SetCat(cp); }
helper.TestCat(cp);
TUniChInfo &ci = h[i]; ci.script = scriptNo; }
}
reader.Close();
scripts.AddDat(GetScriptNameUnknown()) = 0;
printf("TUniChDb::InitScripts: %d scripts: ", scripts.Len());
if (AlwaysFalse()) for (int i = scripts.FFirstKeyId(); scripts.FNextKeyId(i); )
printf(" %d:%s (%d)", i, scripts.GetKey(i).CStr(), int(scripts[i]));
printf("\n");
}


| void TUniChDb::InitSpecialCasing | ( | const TStr & | basePath | ) | [protected] |
Definition at line 1225 of file unicode.cpp.
References THash< TKey, TDat, THashFunc >::AddDat(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), TStr::Empty(), TUniChDb::TUcdFileReader::GetNextLine(), GetSpecialCasingFn(), IAssert, TVec< TVal, TSizeTy >::Last(), TVec< TVal, TSizeTy >::Len(), TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePoint(), TUniChDb::TUcdFileReader::ParseCodePointList(), specialCasingLower, specialCasingTitle, and specialCasingUpper.
Referenced by LoadTxt().
{
TUcdFileReader reader; TStrV fields;
reader.Open(CombinePath(basePath, GetSpecialCasingFn()));
while (reader.GetNextLine(fields))
{
IAssert(fields.Len() == 5 || fields.Len() == 6);
IAssert(fields.Last().Empty());
// Skip conditional mappings -- they will be hardcoded in the GetCaseConverted method.
TStr conditions = "";
if (fields.Len() == 6) conditions = fields[4];
conditions.ToTrunc(); if (! conditions.Empty()) continue;
// Keep the other mappings.
const int cp = reader.ParseCodePoint(fields[0]);
TIntV v; reader.ParseCodePointList(fields[1], v);
specialCasingLower.AddDat(cp, v);
reader.ParseCodePointList(fields[2], v);
specialCasingTitle.AddDat(cp, v);
reader.ParseCodePointList(fields[3], v);
specialCasingUpper.AddDat(cp, v);
}
reader.Close();
}

| void TUniChDb::InitWordAndSentenceBoundaryFlags | ( | const TStr & | basePath | ) | [protected] |
Definition at line 1100 of file unicode.cpp.
References TVec< TVal, TSizeTy >::Add(), THash< TKey, TDat, THashFunc >::AddDat(), TUniChDb::TUcdFileReader::Close(), TUniChInfo::ClrWbAndSbFlags(), anonymous_namespace{unicode.cpp}::CombinePath(), TStr::CStr(), Fail, FailR, THash< TKey, TDat, THashFunc >::FFirstKeyId(), THash< TKey, TDat, THashFunc >::FNextKeyId(), GetAuxiliaryDir(), THash< TKey, TDat, THashFunc >::GetDat(), THash< TKey, TDat, THashFunc >::GetKey(), THash< TKey, TDat, THashFunc >::GetKeyId(), TUniChDb::TUcdFileReader::GetNextLine(), TUniChInfo::GetSbFlags(), TUniChInfo::GetSbFlagsStr(), GetScriptByName(), GetScriptNameHiragana(), GetScriptNameKatakana(), GetSentenceBreakPropertyFn(), TUniChInfo::GetWbFlags(), GetWordBreakPropertyFn(), h, IAssert, TUniChInfo::IsAlphabetic(), TUniChInfo::IsGraphemeExtend(), TUniChInfo::IsIdeographic(), THash< TKey, TDat, THashFunc >::IsKey(), TUniChInfo::IsLowercase(), TUniChInfo::IsSbFlag(), TUniChInfo::IsSTerminal(), TUniChInfo::IsUppercase(), TUniChInfo::IsWbFlag(), TUniChInfo::IsWhiteSpace(), TVec< TVal, TSizeTy >::Len(), TUniChInfo::lineBreak, TUniChInfo::LineBreak_ComplexContext, TUniChInfo::LineBreak_InfixNumeric, TUniChInfo::LineBreak_Numeric, TUniChInfo::LineBreak_Quotation, TVec< TVal, TSizeTy >::Merge(), TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePointRange(), TUniChInfo::script, TUniChInfo::SetSbFlag(), TUniChInfo::SetWbFlag(), TVec< TVal, TSizeTy >::Sort(), TUniChInfo::subCat, ucfCompatibilityDecomposition, ucfSbATerm, ucfSbClose, ucfSbFormat, ucfSbLower, ucfSbNumeric, ucfSbOLetter, ucfSbSep, ucfSbSp, ucfSbSTerm, ucfSbUpper, ucfWbALetter, ucfWbExtendNumLet, ucfWbFormat, ucfWbKatakana, ucfWbMidLetter, ucfWbMidNum, ucfWbNumeric, and anonymous_namespace{unicode.cpp}::VB.
Referenced by LoadTxt().
{
// UAX #29, sec. 4.1 and 5.1.
// Note: these flags can also be initialized from auxiliary\\WordBreakProperty.txt.
int katakana = GetScriptByName(GetScriptNameKatakana()); IAssert(katakana >= 0);
int hiragana = GetScriptByName(GetScriptNameHiragana()); IAssert(hiragana >= 0);
// Clear any existing word-boundary flags and initialize them again.
for (int i = h.FFirstKeyId(); h.FNextKeyId(i); )
{
const int cp = h.GetKey(i); TUniChInfo& ci = h[i];
ci.ClrWbAndSbFlags();
// Word-boundary flags.
if (ci.subCat == ucOtherFormat && cp != 0x200c && cp != 0x200d) ci.SetWbFlag(ucfWbFormat);
if (ci.script == katakana) ci.SetWbFlag(ucfWbKatakana);
if (ci.lineBreak == TUniChInfo::LineBreak_InfixNumeric && cp != 0x3a) ci.SetWbFlag(ucfWbMidNum);
if (ci.lineBreak == TUniChInfo::LineBreak_Numeric) ci.SetWbFlag(ucfWbNumeric);
if (ci.subCat == ucPunctuationConnector) ci.SetWbFlag(ucfWbExtendNumLet);
// Sentence-boundary flags. Some are identical to some word-boundary flags.
if (cp == 0xa || cp == 0xd || cp == 0x85 || cp == 0x2028 || cp == 0x2029) ci.SetSbFlag(ucfSbSep);
if (ci.subCat == ucOtherFormat && cp != 0x200c && cp != 0x200d) ci.SetSbFlag(ucfSbFormat);
if (ci.IsWhiteSpace() && ! ci.IsSbFlag(ucfSbSep) && cp != 0xa0) ci.SetSbFlag(ucfSbSp);
if (ci.IsLowercase() && ! ci.IsGraphemeExtend()) ci.SetSbFlag(ucfSbLower);
if (ci.IsUppercase() || ci.subCat == ucLetterTitlecase) ci.SetSbFlag(ucfSbUpper);
if ((ci.IsAlphabetic() || cp == 0xa0 || cp == 0x5f3) && ! ci.IsSbFlag(ucfSbLower) && ! ci.IsSbFlag(ucfSbUpper) && ! ci.IsGraphemeExtend()) ci.SetSbFlag(ucfSbOLetter);
if (ci.lineBreak == TUniChInfo::LineBreak_Numeric) ci.SetSbFlag(ucfSbNumeric);
if (cp == 0x2e) ci.SetSbFlag(ucfSbATerm);
// Note: UAX #29 says that if the property STerm = true, then the character should belong to the STerm class for
// the purposes of sentence-boundary detection. Now in PropList.txt there is no doubt that 002E has the STerm
// property; thus, it should also belong to the STerm sentence-boundary class. However, in
// SentenceBreakProperty.txt, 002E is only listed in the ATerm class, but not in the STerm class.
if (ci.IsSTerminal() && cp != 0x2e) ci.SetSbFlag(ucfSbSTerm);
if ((ci.subCat == ucPunctuationOpen || ci.subCat == ucPunctuationClose || ci.lineBreak == TUniChInfo::LineBreak_Quotation) && cp != 0x5f3 && ! ci.IsSbFlag(ucfSbATerm) && ! ci.IsSbFlag(ucfSbSTerm)) ci.SetSbFlag(ucfSbClose);
}
// Some additional characters for Katakana and MidLetter.
TIntV v = (VB, 0x3031, 0x3032, 0x3033, 0x3034, 0x3035, 0x309b, 0x309c, 0x30a0, 0x30fc, 0xff70, 0xff9e, 0xff9f);
for (int i = 0; i < v.Len(); i++) h.GetDat(v[i]).SetWbFlag(ucfWbKatakana);
v = (VB, 0x27, 0xb7, 0x5f4, 0x2019, 0x2027, 0x3a);
for (int i = 0; i < v.Len(); i++) h.GetDat(v[i]).SetWbFlag(ucfWbMidLetter);
// WbALetter depends on Katakana, so it cannot be initialized earlier.
for (int i = h.FFirstKeyId(); h.FNextKeyId(i); )
{
const int cp = h.GetKey(i); TUniChInfo& ci = h[i];
if ((ci.IsAlphabetic() || cp == 0x5f3) && ! ci.IsIdeographic() && ! ci.IsWbFlag(ucfWbKatakana) && ci.lineBreak != TUniChInfo::LineBreak_ComplexContext && ci.script != hiragana && ! ci.IsGraphemeExtend())
ci.SetWbFlag(ucfWbALetter);
}
// An alternative is to extract the flags from WordBreakProperty.txt.
// The results should be the same.
{TUcdFileReader reader; TStrV fields;
reader.Open(CombinePath(CombinePath(basePath, GetAuxiliaryDir()), GetWordBreakPropertyFn()));
THash<TInt, TInt> hh;
while (reader.GetNextLine(fields))
{
IAssert(fields.Len() == 2);
int from, to; reader.ParseCodePointRange(fields[0], from, to);
TStr s = fields[1];
TUniChFlags flag = ucfCompatibilityDecomposition;
if (s == "Format") flag = ucfWbFormat;
else if (s == "Katakana") flag = ucfWbKatakana;
else if (s == "ALetter") flag = ucfWbALetter;
else if (s == "MidLetter") flag = ucfWbMidLetter;
else if (s == "MidNum") flag = ucfWbMidNum;
else if (s == "Numeric") flag = ucfWbNumeric;
else if (s == "ExtendNumLet") flag = ucfWbExtendNumLet;
else FailR(s.CStr());
for (int c = from; c <= to; c++) {
int i = hh.GetKeyId(c); if (i < 0) hh.AddDat(c, flag);
else hh[i].Val |= flag; }
}
reader.Close();
TIntV cps; for (int i = h.FFirstKeyId(); h.FNextKeyId(i); ) cps.Add(h.GetKey(i));
for (int i = hh.FFirstKeyId(); hh.FNextKeyId(i); ) cps.Add(hh.GetKey(i));
cps.Sort(); cps.Merge();
for (int i = 0; i < cps.Len(); i++)
{
int cp = cps[i];
int flags1 = 0; if (h.IsKey(cp)) flags1 = h.GetDat(cp).GetWbFlags();
int flags2 = 0; if (hh.IsKey(cp)) flags2 = hh.GetDat(cp);
flags1 &= ~ucfSbSep; flags2 &= ~ucfSbSep;
if (flags1 != flags2) {
printf("cp = %04x: flags1 = %08x flags2 = %08x xor = %08x\n", cp, flags1, flags2, flags1 ^ flags2);
Fail; }
}}
// Likewise, for sentence boundary flags we have SentenceBreakProperty.txt.
{TUcdFileReader reader; TStrV fields;
reader.Open(CombinePath(CombinePath(basePath, GetAuxiliaryDir()), GetSentenceBreakPropertyFn()));
THash<TInt, TInt> hh;
while (reader.GetNextLine(fields))
{
IAssert(fields.Len() == 2);
int from, to; reader.ParseCodePointRange(fields[0], from, to);
TStr s = fields[1];
TUniChFlags flag = ucfCompatibilityDecomposition;
if (s == "Sep") flag = ucfSbSep;
else if (s == "Format") flag = ucfSbFormat;
else if (s == "Sp") flag = ucfSbSp;
else if (s == "Lower") flag = ucfSbLower;
else if (s == "Upper") flag = ucfSbUpper;
else if (s == "OLetter") flag = ucfSbOLetter;
else if (s == "Numeric") flag = ucfSbNumeric;
else if (s == "ATerm") flag = ucfSbATerm;
else if (s == "STerm") flag = ucfSbSTerm;
else if (s == "Close") flag = ucfSbClose;
else FailR(s.CStr());
for (int c = from; c <= to; c++) {
int i = hh.GetKeyId(c); if (i < 0) hh.AddDat(c, flag);
else hh[i].Val |= flag; }
}
reader.Close();
TIntV cps; for (int i = h.FFirstKeyId(); h.FNextKeyId(i); ) cps.Add(h.GetKey(i));
for (int i = hh.FFirstKeyId(); hh.FNextKeyId(i); ) cps.Add(hh.GetKey(i));
cps.Sort(); cps.Merge();
for (int i = 0; i < cps.Len(); i++)
{
int cp = cps[i];
int flags1 = 0; if (h.IsKey(cp)) flags1 = h.GetDat(cp).GetSbFlags();
int flags2 = 0; if (hh.IsKey(cp)) flags2 = hh.GetDat(cp);
if (flags1 != flags2) {
printf("cp = %04x: flags1 = %08x [%s] flags2 = %08x [%s] xor = %08x\n", cp,
flags1, TUniChInfo::GetSbFlagsStr(flags1).CStr(),
flags2, TUniChInfo::GetSbFlagsStr(flags2).CStr(),
flags1 ^ flags2);
Fail; }
}}
}

| bool TUniChDb::IsGetChInfo | ( | const int | cp, |
| TUniChInfo & | ChInfo | ||
| ) | [inline] |
| DECLARE_FORWARDED_PROPERTY_METHODS bool TUniChDb::IsPrivateUse | ( | const int | cp | ) | const [inline] |
Definition at line 1383 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
{
int i = h.GetKeyId(cp); if (i >= 0) return h[i].IsPrivateUse();
return (0xe000 <= cp && cp <= 0xf8ff) || // plane 0 private-use area
// Planes 15 and 16 are entirely for private use.
(0xf0000 <= cp && cp <= 0xffffd) || (0x100000 <= cp && cp <= 0x10fffd); }

| bool TUniChDb::IsSbFlag | ( | const int | cp, |
| const TUniChFlags | flag | ||
| ) | const [inline] |
| bool TUniChDb::IsSurrogate | ( | const int | cp | ) | const [inline] |
| bool TUniChDb::IsWbFlag | ( | const int | cp, |
| const TUniChFlags | flag | ||
| ) | const [inline] |
| static bool TUniChDb::IsWbIgnored | ( | const TUniChInfo & | ci | ) | [inline, static, protected] |
Definition at line 1419 of file unicode.h.
References TUniChInfo::IsGbExtend(), and TUniChInfo::IsWbFormat().
Referenced by FindNextSentenceBoundary(), FindNextWordBoundary(), TestFindNextWordOrSentenceBoundary(), TestWbFindNonIgnored(), WbFindCurOrNextNonIgnored(), WbFindNextNonIgnored(), WbFindNextNonIgnoredS(), and WbFindPrevNonIgnored().
{ return ci.IsGbExtend() || ci.IsWbFormat(); }

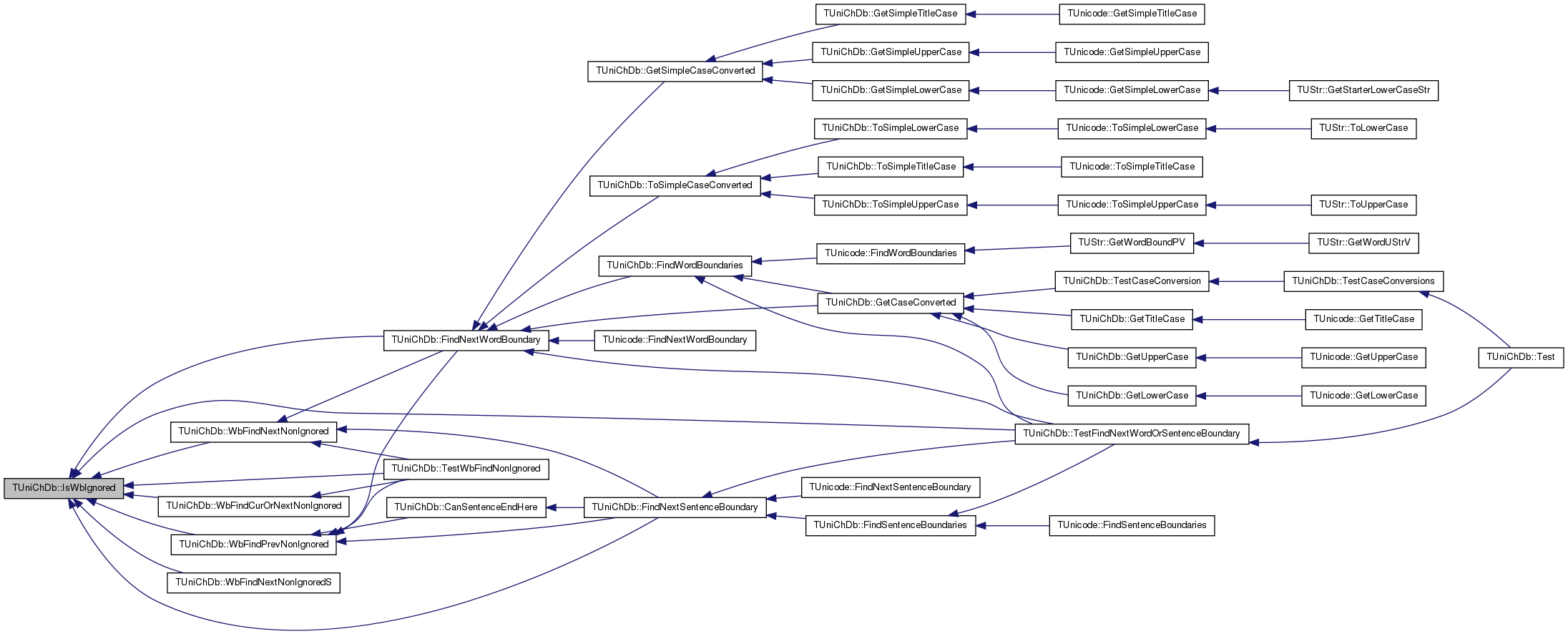
| bool TUniChDb::IsWbIgnored | ( | const int | cp | ) | const [inline, protected] |
Definition at line 1420 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), h, and IsWbIgnored().
Referenced by IsWbIgnored().
{ int i = h.GetKeyId(cp); if (i < 0) return false; else return IsWbIgnored(h[i]); }


| void TUniChDb::Load | ( | TSIn & | SIn | ) | [inline] |
Definition at line 1285 of file unicode.h.
References caseFolding, charNames, decompositions, h, InitAfterLoad(), inverseDec, THash< TKey, TDat, THashFunc >::Load(), TUniCaseFolding::Load(), TVec< TVal, TSizeTy >::Load(), TSIn::LoadCs(), scripts, specialCasingLower, specialCasingTitle, specialCasingUpper, and TStrPool::~TStrPool().
Referenced by LoadBin(), Test(), and TUniChDb().
{
h.Load(SIn); charNames.~TStrPool(); new (&charNames) TStrPool(SIn);
decompositions.Load(SIn);
inverseDec.Load(SIn); caseFolding.Load(SIn); scripts.Load(SIn);
specialCasingLower.Load(SIn); specialCasingUpper.Load(SIn); specialCasingTitle.Load(SIn);
SIn.LoadCs(); InitAfterLoad(); }
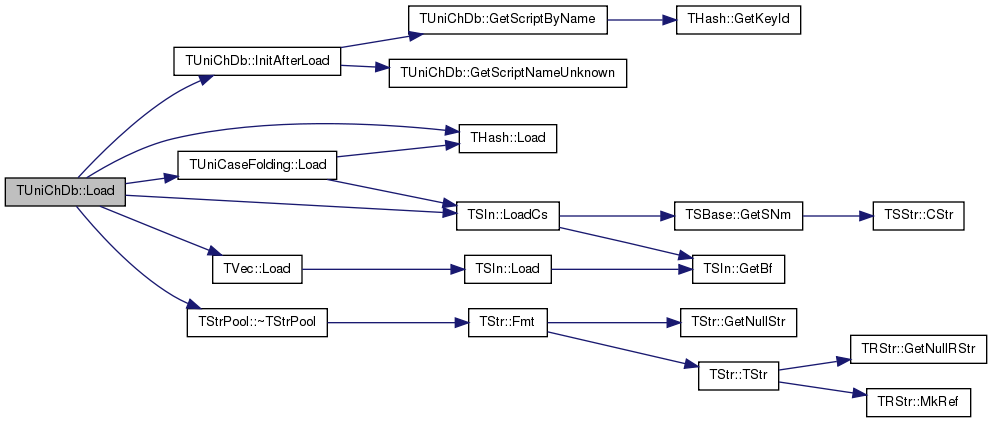

| void TUniChDb::LoadBin | ( | const TStr & | fnBin | ) | [inline] |
Definition at line 1291 of file unicode.h.
References Load(), and TFIn::New().
Referenced by TUnicode::TUnicode().
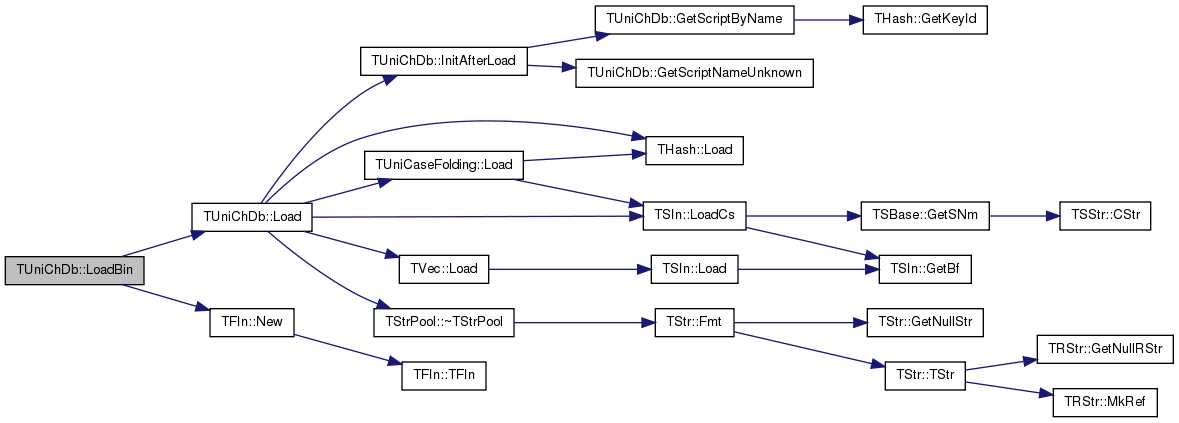

| void TUniChDb::LoadTxt | ( | const TStr & | basePath | ) |
Definition at line 1249 of file unicode.cpp.
References THash< TKey, TDat, THashFunc >::AddDat(), THash< TKey, TDat, THashFunc >::AddKey(), TStrPool::AddStr(), caseFolding, TUniChInfo::ccInvalid, TUniChInfo::ccStarter, charNames, TUniChInfo::chCat, TUniChInfo::chSubCat, TUniChDb::TUcdFileReader::Close(), Clr(), TUniChInfo::combClass, anonymous_namespace{unicode.cpp}::CombinePath(), TStr::CStr(), TUniChInfo::decompOffset, decompositions, TStr::Empty(), THash< TKey, TDat, THashFunc >::FFirstKeyId(), TUniChInfo::flags, THash< TKey, TDat, THashFunc >::FNextKeyId(), GetCaseFoldingFn(), GetCompositionExclusionsFn(), THash< TKey, TDat, THashFunc >::GetDat(), THash< TKey, TDat, THashFunc >::GetKey(), THash< TKey, TDat, THashFunc >::GetKeyId(), TUniChDb::TUcdFileReader::GetNextLine(), GetScriptByName(), GetScriptNameUnknown(), GetUnicodeDataFn(), h, HangulSBase, HangulSCount, IAssert, IAssertR, TUniChInfo::InitAfterLoad(), InitDerivedCoreProperties(), InitLineBreaks(), InitPropList(), InitScripts(), InitSpecialCasing(), InitWordAndSentenceBoundaryFlags(), inverseDec, TUniChInfo::IsCompatibilityDecomposition(), TUniChInfo::IsCompositionExclusion(), TStr::IsInt(), THash< TKey, TDat, THashFunc >::IsKey(), THash< TKey, TDat, THashFunc >::Len(), TStr::Len(), TVec< TVal, TSizeTy >::Len(), TUniCaseFolding::LoadTxt(), LoadTxt_ProcessDecomposition(), TUCh::Mn, TUCh::Mx, TUniChInfo::nameOffset, TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePoint(), TUniChInfo::script, scriptUnknown, TUniChInfo::simpleLowerCaseMapping, TUniChInfo::simpleTitleCaseMapping, TUniChInfo::simpleUpperCaseMapping, and ucfCompositionExclusion.
Referenced by Test().
{
Clr();
// Set up a hash table with enough ports that there will be more or less no chains longer than 1 element.
h = THash<TInt, TUniChInfo>(196613, true);
//
caseFolding.LoadTxt(CombinePath(basePath, GetCaseFoldingFn()));
//
TUcdFileReader reader; TStrV fields; TIntH seen;
reader.Open(CombinePath(basePath, GetUnicodeDataFn()));
while (reader.GetNextLine(fields))
{
// Codepoint.
int cp = reader.ParseCodePoint(fields[0]);
IAssert(! seen.IsKey(cp)); seen.AddKey(cp);
TUniChInfo& ci = h.AddDat(cp);
// Name.
ci.nameOffset = charNames.AddStr(fields[1]);
// Category.
TStr& s = fields[2]; IAssert(s.Len() == 2);
ci.chCat = s[0]; ci.chSubCat = s[1];
// Canonical combining class.
s = fields[3]; IAssert(s.Len() > 0);
int i; bool ok = s.IsInt(true, TUCh::Mn, TUCh::Mx, i); IAssertR(ok, s);
ci.combClass = (uchar) i;
// Decomposition type and mapping.
LoadTxt_ProcessDecomposition(ci, fields[5]);
// Simple case mappings.
s = fields[12]; ci.simpleUpperCaseMapping = (! s.Empty() ? reader.ParseCodePoint(s) : -1);
s = fields[13]; ci.simpleLowerCaseMapping = (! s.Empty() ? reader.ParseCodePoint(s) : -1);
s = fields[14]; ci.simpleTitleCaseMapping = (! s.Empty() ? reader.ParseCodePoint(s) : -1);
//
ci.InitAfterLoad(); // initializes ci.cat, ci.subCat
}
reader.Close();
//
InitScripts(basePath);
//
InitPropList(basePath);
InitDerivedCoreProperties(basePath);
InitLineBreaks(basePath);
InitSpecialCasing(basePath);
// Process the composition exclusions (UAX #15, sec. 6).
for (int i = h.FFirstKeyId(); h.FNextKeyId(i); )
{
TUniChInfo& ci = h[i];
int ofs = ci.decompOffset; if (ofs < 0) continue;
int n = 0; while (decompositions[ofs + n] >= 0) n++;
IAssert(n > 0);
// Singleton decompositions.
if (n == 1) { ci.flags |= ucfCompositionExclusion; continue; }
// Non-starter decompositions.
int cp1 = decompositions[ofs];
IAssert(h.IsKey(cp1));
uchar ccc = h.GetDat(cp1).combClass;
if (ccc != TUniChInfo::ccStarter) { ci.flags |= ucfCompositionExclusion; continue; }
}
// Process the composition exclusion table.
reader.Open(CombinePath(basePath, GetCompositionExclusionsFn()));
int nExclusionTable = 0;
while (reader.GetNextLine(fields))
{
IAssert(fields.Len() == 1);
int cp = reader.ParseCodePoint(fields[0]);
int i = h.GetKeyId(cp); IAssert(i >= 0);
h[i].flags |= ucfCompositionExclusion;
nExclusionTable++;
}
reader.Close();
// Prepare the inverted index for composition pairs.
for (int i = h.FFirstKeyId(); h.FNextKeyId(i); )
{
int cp = h.GetKey(i);
TUniChInfo& ci = h[i];
int ofs = ci.decompOffset; if (ofs < 0) continue;
if (ci.IsCompositionExclusion()) continue;
if (ci.IsCompatibilityDecomposition()) continue;
int n = 0; while (decompositions[ofs + n] >= 0) n++;
if (n != 2) continue;
TIntPr pr = TIntPr(decompositions[ofs], decompositions[ofs + 1]);
IAssert(! inverseDec.IsKey(pr));
IAssert(ci.combClass == TUniChInfo::ccStarter);
inverseDec.AddDat(pr, cp);
}
printf("TUniChDb(%s): %d chars in h, %d in decomp inverse index; %d in decomp vector; %d in exclusion table\n",
basePath.CStr(), h.Len(), inverseDec.Len(), decompositions.Len(), nExclusionTable);
// Before calling InitWordBoundaryFlags(), scripts must have been initialized, as well as
// flags such as Alphabetic, Word_Break, and Grapheme_Extend.
InitWordAndSentenceBoundaryFlags(basePath); // Note: scripts must have been initialized by this point.
// Make sure that Hangul combined characters are treated as stareters.
for (int cp = HangulSBase; cp < HangulSBase + HangulSCount; cp++)
{
int j = h.GetKeyId(cp); if (j < 0) continue;
TUniChInfo& ci = h[j];
if (ci.combClass == TUniChInfo::ccInvalid) ci.combClass = TUniChInfo::ccStarter;
IAssert(ci.combClass == TUniChInfo::ccStarter);
}
// There should be no more additions to 'h' beyond this point.
const int oldHLen = h.Len();
// Provide default (identity) case mappings if any were missing from UnicodeData.txt
// (or if any entirely new characters were added later, e.g. while reading LineBreaks.txt).
int scriptUnknown = GetScriptByName(GetScriptNameUnknown());
for (int i = h.FFirstKeyId(); h.FNextKeyId(i); )
{
int cp = h.GetKey(i); TUniChInfo &ci = h[i];
if (ci.simpleLowerCaseMapping < 0) ci.simpleLowerCaseMapping = cp;
if (ci.simpleUpperCaseMapping < 0) ci.simpleUpperCaseMapping = cp;
if (ci.simpleTitleCaseMapping < 0) ci.simpleTitleCaseMapping = cp;
if (ci.script < 0) ci.script = scriptUnknown;
}
IAssert(h.Len() == oldHLen);
}


| void TUniChDb::LoadTxt_ProcessDecomposition | ( | TUniChInfo & | ci, |
| TStr | s | ||
| ) | [protected] |
Definition at line 937 of file unicode.cpp.
References TVec< TVal, TSizeTy >::Add(), TVec< TVal, TSizeTy >::AddV(), TUniChInfo::decompOffset, decompositions, TStr::Empty(), TUniChInfo::flags, TStr::GetSubStr(), IAssert, TStr::Len(), TVec< TVal, TSizeTy >::Len(), TUniChDb::TUcdFileReader::ParseCodePointList(), TStr::SearchCh(), TStr::ToTrunc(), and ucfCompatibilityDecomposition.
Referenced by LoadTxt().
{
if (s.Empty()) return;
if (s[0] == '<') {
int i = s.SearchCh('>'); IAssert(i > 0);
ci.flags |= ucfCompatibilityDecomposition;
s = s.GetSubStr(i + 1, s.Len() - 1); s.ToTrunc(); }
TIntV dec; TUcdFileReader::ParseCodePointList(s, dec);
IAssert(dec.Len() > 0);
ci.decompOffset = decompositions.Len();
decompositions.AddV(dec); decompositions.Add(-1);
}


| void TUniChDb::PrintCharNames | ( | FILE * | f, |
| const TSrcVec & | src, | ||
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| const TStr & | prefix | ||
| ) | const [inline] |
Definition at line 1336 of file unicode.h.
References TStr::CStr(), and GetCharNameS().
{
if (! f) f = stdout;
for (const size_t srcEnd = srcIdx + srcCount; srcIdx < srcEnd; srcIdx++) {
fprintf(f, "%s", prefix.CStr());
int cp = src[TVecIdx(srcIdx)]; fprintf(f, (cp >= 0x10000 ? "U+%05x" : "U+%04x "), cp);
fprintf(f, " %s\n", GetCharNameS(cp).CStr()); }}

| void TUniChDb::PrintCharNames | ( | FILE * | f, |
| const TSrcVec & | src, | ||
| const TStr & | prefix | ||
| ) | const [inline] |
Definition at line 1342 of file unicode.h.
References PrintCharNames().
Referenced by PrintCharNames().
{ PrintCharNames(f, src, 0, src.Len(), prefix); }


| void TUniChDb::Save | ( | TSOut & | SOut | ) | const [inline] |
Definition at line 1280 of file unicode.h.
References caseFolding, charNames, decompositions, h, inverseDec, THash< TKey, TDat, THashFunc >::Save(), TUniCaseFolding::Save(), TVec< TVal, TSizeTy >::Save(), TStrPool::Save(), TSOut::SaveCs(), scripts, specialCasingLower, specialCasingTitle, and specialCasingUpper.
Referenced by SaveBin(), and Test().
{
h.Save(SOut); charNames.Save(SOut); decompositions.Save(SOut);
inverseDec.Save(SOut); caseFolding.Save(SOut); scripts.Save(SOut);
specialCasingLower.Save(SOut); specialCasingUpper.Save(SOut); specialCasingTitle.Save(SOut);
SOut.SaveCs(); }


| void TUniChDb::SaveBin | ( | const TStr & | fnBinUcd | ) |
Definition at line 1362 of file unicode.cpp.
References TFOut::New(), and Save().
{
PSOut SOut=TFOut::New(fnBinUcd);
Save(*SOut);
}
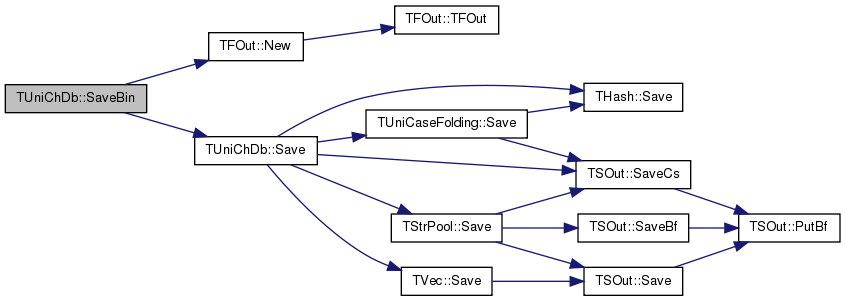
| void TUniChDb::SbEx_Add | ( | const TSrcVec & | v | ) | [inline] |
Definition at line 1490 of file unicode.h.
References TUniTrie< TItem_ >::Add(), and sbExTrie.
Referenced by SbEx_Add(), SbEx_AddMulti(), and SbEx_AddUtf8().


| void TUniChDb::SbEx_Add | ( | const TStr & | s | ) | [inline] |
Definition at line 1492 of file unicode.h.
References TVec< TVal, TSizeTy >::Gen(), TStr::Len(), and SbEx_Add().
{
TIntV v; int n = s.Len(); v.Gen(n); for (int i = 0; i < n; i++) v[i] = int(uchar(s[i])); SbEx_Add(v); }
| int TUniChDb::SbEx_AddMulti | ( | const TStr & | words, |
| const bool | wordsAreUtf8 = true |
||
| ) | [inline] |
Definition at line 1495 of file unicode.h.
References TVec< TVal, TSizeTy >::Len(), SbEx_Add(), SbEx_AddUtf8(), and TStr::SplitOnAllCh().
Referenced by SbEx_SetStdEnglish().
{ TStrV vec; words.SplitOnAllCh('|', vec);
for (int i = 0; i < vec.Len(); i++) if (wordsAreUtf8) SbEx_AddUtf8(vec[i]); else SbEx_Add(vec[i]);
return vec.Len(); }

| void TUniChDb::SbEx_AddUtf8 | ( | const TStr & | s | ) | [inline] |
Definition at line 1494 of file unicode.h.
References TUniCodec::DecodeUtf8(), and SbEx_Add().
Referenced by SbEx_AddMulti().
{ TUniCodec codec; TIntV v; codec.DecodeUtf8(s, v); SbEx_Add(v); }

| void TUniChDb::SbEx_Clr | ( | ) | [inline] |
Definition at line 1489 of file unicode.h.
References TUniTrie< TItem_ >::Clr(), and sbExTrie.
Referenced by TUnicode::ClrSentenceBoundaryExceptions(), and SbEx_SetStdEnglish().


| void TUniChDb::SbEx_Set | ( | const TUniTrie< TInt > & | newTrie | ) | [inline] |
| int TUniChDb::SbEx_SetStdEnglish | ( | ) | [inline] |
Definition at line 1499 of file unicode.h.
References SbEx_AddMulti(), and SbEx_Clr().
Referenced by TUnicode::UseEnglishSentenceBoundaryExceptions().
{
static const TStr data = "Ms|Mrs|Mr|Rev|Dr|Prof|Gov|Sen|Rep|Gen|Brig|Col|Capt|Lieut|Lt|Sgt|Pvt|Cmdr|Adm|Corp|St|Mt|Ft|e.g|e. g.|i.e|i. e|ib|ibid|s.v|s. v|s.vv|s. vv";
SbEx_Clr(); return SbEx_AddMulti(data, false); }

| void TUniChDb::Test | ( | const TStr & | basePath | ) |
Definition at line 1377 of file unicode.cpp.
References caseFolding, anonymous_namespace{unicode.cpp}::CombinePath(), TFile::Exists(), GetBinFn(), Load(), LoadTxt(), TFIn::New(), TFOut::New(), Save(), TUniCaseFolding::Test(), TestCaseConversions(), TestComposition(), TestFindNextWordOrSentenceBoundary(), TestWbFindNonIgnored(), and TUniChDb().
{
TStr fnBin = CombinePath(basePath, GetBinFn());
if (true || ! TFile::Exists(fnBin))
{
// Test LoadTxt.
LoadTxt(basePath);
// Test Save.
{PSOut SOut = TFOut::New(fnBin);
Save(*SOut);}
}
// Test Load.
this->~TUniChDb();
new(this) TUniChDb();
{PSIn SIn = TFIn::New(fnBin);
Load(*SIn);}
// Test the case folding.
caseFolding.Test();
// Test the word breaking.
TestWbFindNonIgnored();
// Test the sentence breaking.
TestFindNextWordOrSentenceBoundary(basePath, true);
TestFindNextWordOrSentenceBoundary(basePath, false);
// Test composition and decomposition.
TestComposition(basePath);
// Test the case conversions.
TestCaseConversions();
}

| void TUniChDb::TestCaseConversion | ( | const TStr & | source, |
| const TStr & | trueLc, | ||
| const TStr & | trueTc, | ||
| const TStr & | trueUc, | ||
| bool | turkic, | ||
| bool | lithuanian | ||
| ) | [protected] |
Definition at line 825 of file unicode.cpp.
References ccLower, ccTitle, ccUpper, GetCaseConverted(), IAssert, TVec< TVal, TSizeTy >::Len(), and TUniChDb::TUcdFileReader::ParseCodePointList().
Referenced by TestCaseConversions().
{
TIntV src;
TUcdFileReader::ParseCodePointList(source, src);
FILE *f = stderr;
for (int i = 0; i < 3; i++)
{
TCaseConversion how = (i == 0) ? ccLower : (i == 1) ? ccTitle : ccUpper;
const TStr &trueDestS = (how == ccLower ? trueLc : how == ccTitle ? trueTc : trueUc);
TIntV trueDest; TUcdFileReader::ParseCodePointList(trueDestS, trueDest);
TIntV dest;
GetCaseConverted(src, 0, src.Len(), dest, true, how, turkic, lithuanian);
bool ok = (dest.Len() == trueDest.Len());
if (ok) for (int i = 0; i < dest.Len() && ok; i++) ok = ok && (dest[i] == trueDest[i]);
if (ok) continue;
fprintf(f, "%s(", (how == ccLower ? "toLowercase" : how == ccTitle ? "toTitlecase" : "toUppercase"));
for (int i = 0; i < src.Len(); i++) fprintf(f, "%s%04x", (i == 0 ? "" : " "), int(src[i]));
fprintf(f, ")\nCorrect: (");
for (int i = 0; i < trueDest.Len(); i++) fprintf(f, "%s%04x", (i == 0 ? "" : " "), int(trueDest[i]));
fprintf(f, ")\nOur output:(");
for (int i = 0; i < dest.Len(); i++) fprintf(f, "%s%04x", (i == 0 ? "" : " "), int(dest[i]));
fprintf(f, ")\n");
IAssert(ok);
}
}
| void TUniChDb::TestCaseConversions | ( | ) | [protected] |
Definition at line 853 of file unicode.cpp.
References TestCaseConversion().
Referenced by Test().
{
// Because no thorough case-conversion test files have been provided as part
// of the Unicode standard, we'll have to test things on a few test cases of our own.
// - First, test some unconditional special mappings, such as 'ss', 'ffl', 'dz', etc.
const TStr F = "0046 ", L = "004C ", S = "0053 ", T = "0054 ", W = "0057 ";
const TStr f = "0066 ", l = "006c ", s = "0073 ", t = "0074 ", w = "0077 ";
const TStr ss = "00df ", ffl = "fb04 ", longs = "017f ", longst = "fb05 ", wRing = "1e98 ", Ring = "030a ";
const TStr DZ = "01c4 ", Dz = "01c5 ", dz = "01c6 ";
const TStr space = "0020 ", Grave = "0300 ";
TestCaseConversion(
F + L + s + t + space + Dz + w + T + ss + wRing + space + longs + DZ + space + dz + longst, // source
f + l + s + t + space + dz + w + t + ss + wRing + space + longs + dz + space + dz + longst, // lowercase
F + l + s + t + space + Dz + w + t + ss + wRing + space + S + dz + space + Dz + longst, // titlecase
F + L + S + T + space + DZ + W + T + S + S + W + Ring + space + S + DZ + space + DZ + S + T, // uppercase
false, false);
// - Dotted I, dotless i, etc., but with turkic == false.
const TStr I = "0049 ", J = "004a ", i = "0069 ", j = "006a ", iDotless = "0131 ", IDot = "0130 ", DotA = "0307 ";
TestCaseConversion(
s + I + t + i + w + iDotless + f + IDot + l + space + iDotless + DotA + f + I + DotA + s, // source
s + i + t + i + w + iDotless + f + i + DotA + l + space + iDotless + DotA + f + i + DotA + s, // lowercase
S + i + t + i + w + iDotless + f + i + DotA + l + space + I + DotA + f + i + DotA + s, // titlecase
S + I + T + I + W + I + F + IDot + L + space + I + DotA + F + I + DotA + S, // uppercase
false, false);
// - Sigma (final vs. non-final forms).
const TStr Sigma = "03a3 ", sigma = "03c3 ", fsigma = "03c2 ";
TestCaseConversion(
Sigma + s + space + s + Sigma + space + s + Sigma + s + space + Sigma + S + Sigma + space + Sigma, // source
sigma + s + space + s + fsigma + space + s + sigma + s + space + sigma + s + fsigma + space + sigma, // lowercase
Sigma + s + space + S + fsigma + space + S + sigma + s + space + Sigma + s + fsigma + space + Sigma, // titlecase
Sigma + S + space + S + Sigma + space + S + Sigma + S + space + Sigma + S + Sigma + space + Sigma, // uppercase
false, false);
TestCaseConversion(
sigma + s + space + s + sigma + space + s + sigma + s + space + sigma + S + sigma + space + sigma, // source
sigma + s + space + s + sigma + space + s + sigma + s + space + sigma + s + sigma + space + sigma, // lowercase
Sigma + s + space + S + sigma + space + S + sigma + s + space + Sigma + s + sigma + space + Sigma, // titlecase
Sigma + S + space + S + Sigma + space + S + Sigma + S + space + Sigma + S + Sigma + space + Sigma, // uppercase
false, false);
TestCaseConversion(
fsigma + s + space + s + fsigma + space + s + fsigma + s + space + fsigma + S + fsigma + space + fsigma, // source
fsigma + s + space + s + fsigma + space + s + fsigma + s + space + fsigma + s + fsigma + space + fsigma, // lowercase
Sigma + s + space + S + fsigma + space + S + fsigma + s + space + Sigma + s + fsigma + space + Sigma, // titlecase
Sigma + S + space + S + Sigma + space + S + Sigma + S + space + Sigma + S + Sigma + space + Sigma, // uppercase
false, false);
const TStr nonSA = "0315 0321 0322 "; // characters that are neither ccStarter nor ccAbove
// Special case mappings for Turkic languages:
// - After_I
TestCaseConversion(
s + I + t + i + w + iDotless + f + IDot + l + space + iDotless + DotA + f + I + DotA + J + DotA + I + Grave + DotA + I + DotA + DotA + I + nonSA + DotA + s, // source
s + iDotless + t + i + w + iDotless + f + i + l + space + iDotless + DotA + f + i + j + DotA + iDotless + Grave + DotA + i + DotA + i + nonSA + s, // lowercase
S + iDotless + t + i + w + iDotless + f + i + l + space + I + DotA + f + i + j + DotA + iDotless + Grave + DotA + i + DotA + i + nonSA + s, // titlecase
S + I + T + IDot + W + I + F + IDot + L + space + I + DotA + F + I + DotA + J + DotA + I + Grave + DotA + I + DotA + DotA + I + nonSA + DotA + S, // uppercase
true, false); // turkic
// - Not_Before_Dot
TestCaseConversion(
I + Grave + t + I + DotA + f + I + nonSA + DotA + j + space + I + nonSA + DotA + space + I + Grave + t, // source
iDotless + Grave + t + i + f + i + nonSA + j + space + i + nonSA + space + iDotless + Grave + t, // lowercase
I + Grave + t + i + f + i + nonSA + j + space + I + nonSA + DotA + space + I + Grave + t, // titlecase
I + Grave + T + I + DotA + F + I + nonSA + DotA + J + space + I + nonSA + DotA + space + I + Grave + T, // uppercase
true, false); // turkic
// Special case mappings for Lithuanian:
// - After_Soft_Dotted [note: I + DotA turns into i + DotA + DotA when lowercasing due to More_Above]
TestCaseConversion(
i + DotA + t + i + Grave + DotA + f + i + DotA + DotA + f + i + nonSA + DotA + I + DotA + t + DotA + i + DotA + Grave, // source
i + DotA + t + i + Grave + DotA + f + i + DotA + DotA + f + i + nonSA + DotA + i + DotA + DotA + t + DotA + i + DotA + Grave, // lowercase
I + t + i + Grave + DotA + f + i + DotA + DotA + f + i + nonSA + DotA + i + DotA + DotA + t + DotA + i + DotA + Grave, // titlecase
I + T + I + Grave + DotA + F + I + DotA + F + I + nonSA + I + DotA + T + DotA + I + Grave, // uppercase
false, true); // lithuanian
// - More_Above [note: j + DotA turns into just J when uppercasing due to After_Soft_Dotted]
TestCaseConversion(
J + Grave + space + J + nonSA + DotA + space + j + Grave + space + j + DotA + space + J + nonSA + J + nonSA + Grave + space + j + nonSA, // source
j + DotA + Grave + space + j + DotA + nonSA + DotA + space + j + Grave + space + j + DotA + space + j + nonSA + j + DotA + nonSA + Grave + space + j + nonSA, // lowercase
J + Grave + space + J + nonSA + DotA + space + J + Grave + space + J + space + J + nonSA + j + DotA + nonSA + Grave + space + J + nonSA, // titlecase
J + Grave + space + J + nonSA + DotA + space + J + Grave + space + J + space + J + nonSA + J + nonSA + Grave + space + J + nonSA, // uppercase
false, true); // lithuanian
// SoftDotted [^ Starter Above]* 0307 --(uc,tc)--> brez 0307
// SoftDotted [^ Starter Above]* 0307 --(
//TestCaseConversion("", "", "", "", false, false);
}


| void TUniChDb::TestComposition | ( | const TStr & | basePath | ) | [protected] |
Definition at line 745 of file unicode.cpp.
References TVec< TVal, TSizeTy >::Add(), THash< TKey, TDat, THashFunc >::AddKey(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), THash< TKey, TDat, THashFunc >::FFirstKeyId(), THash< TKey, TDat, THashFunc >::FNextKeyId(), THash< TKey, TDat, THashFunc >::GetKey(), TUniChDb::TUcdFileReader::GetNextLine(), GetNormalizationTestFn(), h, IAssert, THash< TKey, TDat, THashFunc >::IsKey(), TVec< TVal, TSizeTy >::Len(), NFC_, NFD_, NFKC_, NFKD_, TUniChDb::TUcdFileReader::Open(), and TUniChDb::TUcdFileReader::ParseCodePointList().
Referenced by Test().
{
TUcdFileReader reader; TStrV fields; int nLines = 0;
reader.Open(CombinePath(basePath, GetNormalizationTestFn()));
bool inPart1 = false; TIntH testedInPart1;
while (reader.GetNextLine(fields))
{
nLines += 1;
if (fields.Len() == 1) {
IAssert(fields[0].IsPrefix("@Part"));
inPart1 = (fields[0] == "@Part1"); continue; }
IAssert(fields.Len() == 6);
IAssert(fields[5].Len() == 0);
TIntV c1, c2, c3, c4, c5;
reader.ParseCodePointList(fields[0], c1);
reader.ParseCodePointList(fields[1], c2);
reader.ParseCodePointList(fields[2], c3);
reader.ParseCodePointList(fields[3], c4);
reader.ParseCodePointList(fields[4], c5);
TIntV v;
#define AssE_(v1, v2, expl) AssertEq(v1, v2, TStr(expl) + " (line " + TInt::GetStr(nLines) + ")", 0)
#define NFC_(cmpWith, operand) DecomposeAndCompose(operand, 0, operand.Len(), v, false); AssE_(cmpWith, v, #cmpWith " == NFC(" #operand ")")
#define NFD_(cmpWith, operand) Decompose(operand, 0, operand.Len(), v, false); AssE_(cmpWith, v, #cmpWith " == NFD(" #operand ")")
#define NFKC_(cmpWith, operand) DecomposeAndCompose(operand, 0, operand.Len(), v, true); AssE_(cmpWith, v, #cmpWith " == NFKC(" #operand ")")
#define NFKD_(cmpWith, operand) Decompose(operand, 0, operand.Len(), v, true); AssE_(cmpWith, v, #cmpWith " == NFKD(" #operand ")")
// NFD:
NFD_(c3, c1); // c3 == NFD(c1)
NFD_(c3, c2); // c3 == NFD(c2)
NFD_(c3, c3); // c3 == NFD(c3)
NFD_(c5, c4); // c5 == NFD(c4)
NFD_(c5, c5); // c5 == NFD(c5)
// NFC:
NFC_(c2, c1); // c2 == NFC(c1)
NFC_(c2, c2); // c2 == NFC(c2)
NFC_(c2, c3); // c2 == NFC(c3)
NFC_(c4, c4); // c4 == NFC(c4)
NFC_(c4, c5); // c4 == NFC(c5)
// NFKD:
NFKD_(c5, c1); // c5 == NFKD(c1)
NFKD_(c5, c2); // c5 == NFKD(c2)
NFKD_(c5, c3); // c5 == NFKD(c3)
NFKD_(c5, c4); // c5 == NFKD(c4)
NFKD_(c5, c5); // c5 == NFKD(c5)
// NFKC:
NFKC_(c4, c1); // c4 == NFKC(c1)
NFKC_(c4, c2); // c4 == NFKC(c2)
NFKC_(c4, c3); // c4 == NFKC(c3)
NFKC_(c4, c4); // c4 == NFKC(c4)
NFKC_(c4, c5); // c4 == NFKC(c5)
//
if (inPart1) {
IAssert(c1.Len() == 1);
testedInPart1.AddKey(c1[0]); }
}
reader.Close();
// Test other individual codepoints that were not mentioned in part 1.
int nOther = 0;
for (int i = h.FFirstKeyId(); h.FNextKeyId(i); )
{
const int cp = h.GetKey(i), nLines = -1;
if (testedInPart1.IsKey(cp)) continue;
TIntV x, v; x.Add(cp);
NFC_(x, x); // x == NFC(x)
NFD_(x, x); // x == NFD(x)
NFKC_(x, x); // x == NFKC(x)
NFKD_(x, x); // x == NFKD(x)
nOther += 1;
}
#undef AssE_
#undef NFC_
#undef NFD_
#undef NFKC_
#undef NFKD_
printf("TUniChDb::TestComposition: %d lines processed + %d other individual codepoints.\n", nLines, nOther);
}


| void TUniChDb::TestFindNextWordOrSentenceBoundary | ( | const TStr & | basePath, |
| bool | sentence | ||
| ) | [protected] |
Definition at line 649 of file unicode.cpp.
References TVec< TVal, TSizeTy >::Add(), TVec< TVal, TSizeTy >::AddV(), AlwaysFalse(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), TStr::CStr(), Fail, FailR, FindNextSentenceBoundary(), FindNextWordBoundary(), FindSentenceBoundaries(), FindWordBoundaries(), TVec< TVal, TSizeTy >::Gen(), GetAuxiliaryDir(), TUniChDb::TUcdFileReader::GetNextLine(), GetSbFlags(), TUniChInfo::GetSbFlagsStr(), GetSentenceBreakTestFn(), TRnd::GetUniDevInt(), GetWbFlags(), TUniChInfo::GetWbFlagsStr(), GetWordBreakTestFn(), IAssert, IsWbIgnored(), TVec< TVal, TSizeTy >::Len(), TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePoint(), and TVec< TVal, TSizeTy >::PutAll().
Referenced by Test().
{
TUcdFileReader reader; TStrV fields;
reader.Open(CombinePath(CombinePath(basePath, GetAuxiliaryDir()), (sentence ? GetSentenceBreakTestFn() : GetWordBreakTestFn())));
int nLines = 0; TRnd rnd = TRnd(123);
while (reader.GetNextLine(fields))
{
nLines += 1;
IAssert(fields.Len() == 1);
TStrV parts; fields[0].SplitOnWs(parts);
const int n = parts.Len(); IAssert((n % 2) == 1);
TIntV chars; TBoolV isBreak, isPredicted, isPredicted2;
// Each line is a sequence of codepoints, with a \times or \div in between each
// pair of codepoints (as well as at the beginning and the end of the sequence) to
// indicate whether a boundary exists there or not.
for (int i = 0; i < n; i++)
{
const TStr& s = parts[i];
if ((i % 2) == 0) {
if (s == "\xc3\x97") // multiplication sign (U+00D7) in UTF-8
isBreak.Add(false);
else if (s == "\xc3\xb7") // division sign (U+00F7) in UTF-8
isBreak.Add(true);
else FailR(s.CStr()); }
else chars.Add(reader.ParseCodePoint(s));
}
const int m = n / 2; IAssert(chars.Len() == m); IAssert(isBreak.Len() == m + 1);
IAssert(isBreak[0]); IAssert(isBreak[m]);
isPredicted.Gen(m + 1); isPredicted.PutAll(false);
if (AlwaysFalse()) { printf("%3d", nLines); for (int i = 0; i < m; i++) printf(" %04x", int(chars[i])); printf("\n"); }
// We'll insert a few random characters at the beginning of the sequence
// so that srcPos doesn't always begin at 0.
for (int nBefore = 0; nBefore < 5; nBefore++)
{
TIntV chars2; for (int i = 0; i < nBefore; i++) chars2.Add(0, rnd.GetUniDevInt(0x10ffff + 1));
chars2.AddV(chars);
// Use FindNextBoundary to find all the word boundaries.
size_t position = (nBefore > 0 ? nBefore - 1 : nBefore); size_t prevPosition = position;
while (sentence ? FindNextSentenceBoundary(chars2, nBefore, m, position) : FindNextWordBoundary(chars2, nBefore, m, position))
{
IAssert(prevPosition < position);
IAssert(position <= size_t(nBefore + m));
isPredicted[int(position) - nBefore] = true;
prevPosition = position;
}
IAssert(position == size_t(nBefore + m));
if (sentence) FindSentenceBoundaries(chars2, nBefore, m, isPredicted2);
else FindWordBoundaries(chars2, nBefore, m, isPredicted2);
IAssert(isPredicted2.Len() == m + 1);
bool ok = true;
// If we start at 0, the word boundary at the beginning of the sequence was
// not found explicitly, so we'll add it now.
if (nBefore == 0) isPredicted[0] = true;
// Compare the predicted and the true boundaries.
for (int i = 0; i <= m; i++) {
if (isBreak[i] != isPredicted[i]) ok = false;
IAssert(isPredicted2[i] == isPredicted[i]); }
FILE *f = stderr;
if (! ok)
{
fprintf(f, "\nError in line %d:\n", nLines);
fprintf(f, "True: ");
for (int i = 0; i <= m; i++) {
fprintf(f, "%s ", (isBreak[i] ? "|" : "."));
if (i < m) fprintf(f, "%04x ", int(chars[i + nBefore])); }
fprintf(f, "\nPredicted: ");
for (int i = 0; i <= m; i++) {
fprintf(f, "%s ", (isPredicted[i] ? "|" : "."));
if (i < m) {
const int cp = chars[i + nBefore];
TStr s = sentence ? TUniChInfo::GetSbFlagsStr(GetSbFlags(cp)) : TUniChInfo::GetWbFlagsStr(GetWbFlags(cp));
if (IsWbIgnored(cp)) s = "*" + s;
fprintf(f, "%4s ", s.CStr()); }}
fprintf(f, "\n");
Fail;
}
// Test FindNextBoundary if we start in the middle of the sequence,
// i.e. not at an existing boundary.
for (int i = 0; i < m; i++) {
position = i + nBefore; bool ok = sentence ? FindNextSentenceBoundary(chars2, nBefore, m, position) : FindNextWordBoundary(chars2, nBefore, m, position);
IAssert(ok); // at the very least, there should be the 'boundary' at nBefore + m
IAssert(size_t(i + nBefore) < position); IAssert(position <= size_t(nBefore + m));
position -= nBefore;
for (int j = i + 1; j < int(position); j++)
IAssert(! isBreak[j]);
IAssert(isBreak[int(position)]); }
}
}
reader.Close();
printf("TUniChDb::TestFindNext%sBoundary: %d lines processed.\n", (sentence ? "Sentence" : "Word"), nLines);
}

| void TUniChDb::TestWbFindNonIgnored | ( | const TIntV & | src | ) | const [protected] |
Definition at line 579 of file unicode.cpp.
References TVec< TVal, TSizeTy >::Gen(), IAssert, IsWbIgnored(), TVec< TVal, TSizeTy >::Len(), WbFindCurOrNextNonIgnored(), WbFindNextNonIgnored(), and WbFindPrevNonIgnored().
{
int n = src.Len();
TBoolV isIgnored; isIgnored.Gen(n);
for (int i = 0; i < n; i++) isIgnored[i] = IsWbIgnored(src[i]);
TIntV prevNonIgnored, nextNonIgnored, curOrNextNonIgnored;
prevNonIgnored.Gen(n); nextNonIgnored.Gen(n); curOrNextNonIgnored.Gen(n);
FILE *f = 0; // stderr;
for (int srcIdx = 0; srcIdx < n; srcIdx++) for (int srcLen = 1; srcLen < n - srcIdx; srcLen++)
{
int prev = -1;
for (int i = 0; i < srcLen; i++) {
prevNonIgnored[i] = prev;
if (! isIgnored[srcIdx + i]) prev = srcIdx + i; }
int next = srcIdx + srcLen;
for (int i = srcLen - 1; i >= 0; i--) {
nextNonIgnored[i] = next;
if (! isIgnored[srcIdx + i]) next = srcIdx + i;
curOrNextNonIgnored[i] = next; }
if (f) {
fprintf(f, "\nIndex: "); for (int i = 0; i < srcLen; i++) fprintf(f, " %2d", srcIdx + i);
fprintf(f, "\nNonIgn: "); for (int i = 0; i < srcLen; i++) fprintf(f, " %s", (isIgnored[srcIdx + i] ? " ." : " Y"));
fprintf(f, "\nPrevNI: "); for (int i = 0; i < srcLen; i++) fprintf(f, " %2d", int(prevNonIgnored[i]));
fprintf(f, "\nNextNI: "); for (int i = 0; i < srcLen; i++) fprintf(f, " %2d", int(nextNonIgnored[i]));
fprintf(f, "\nCurNextNI: "); for (int i = 0; i < srcLen; i++) fprintf(f, " %2d", int(curOrNextNonIgnored[i]));
fprintf(f, "\n"); }
for (int i = 0; i < srcLen; i++)
{
size_t s;
s = size_t(srcIdx + i); WbFindNextNonIgnored(src, s, size_t(srcIdx + srcLen));
IAssert(s == size_t(nextNonIgnored[i]));
s = size_t(srcIdx + i); WbFindCurOrNextNonIgnored(src, s, size_t(srcIdx + srcLen));
IAssert(s == size_t(curOrNextNonIgnored[i]));
s = size_t(srcIdx + i); bool ok = WbFindPrevNonIgnored(src, size_t(srcIdx), s);
if (prevNonIgnored[i] < 0) { IAssert(! ok); IAssert(s == size_t(srcIdx)); }
else { IAssert(ok); IAssert(s == size_t(prevNonIgnored[i])); }
}
}
}

| void TUniChDb::TestWbFindNonIgnored | ( | ) | const [protected] |
Definition at line 619 of file unicode.cpp.
References TVec< TVal, TSizeTy >::Add(), TStr::CStr(), THash< TKey, TDat, THashFunc >::FFirstKeyId(), TUniChInfo::flags, THash< TKey, TDat, THashFunc >::FNextKeyId(), TVec< TVal, TSizeTy >::Gen(), THash< TKey, TDat, THashFunc >::GetKey(), GetScriptName(), h, IsWbIgnored(), TVec< TVal, TSizeTy >::Len(), TUniChInfo::properties, TUniChInfo::propertiesX, TUniChInfo::script, and TVec< TVal, TSizeTy >::Sort().
Referenced by Test().
{
TIntV chIgnored, chNonIgnored;
FILE *f = 0; // stderr;
for (int i = h.FFirstKeyId(); h.FNextKeyId(i); ) {
const int cp = h.GetKey(i); const TUniChInfo& ci = h[i];
if (f) fprintf(f, "%04x: flags %08x props %08x %08x script \"%s\"\n", cp,
ci.flags, ci.properties, ci.propertiesX, GetScriptName(ci.script).CStr());
(IsWbIgnored(h[i]) ? chIgnored : chNonIgnored).Add(h.GetKey(i));
}
chIgnored.Sort(); chNonIgnored.Sort();
printf("TUniChDb::TestWbNonIgnored: %d ignored, %d nonignored chars.\n", chIgnored.Len(), chNonIgnored.Len());
TRnd rnd = TRnd(123);
for (int iter = 0; iter <= 50; iter++)
{
int percIgnored = 2 * iter;
for (int n = 0; n <= 20; n++)
{
// Prepare a random sequence of 'n' codepoints.
TIntV v; v.Gen(n);
for (int i = 0; i < n; i++) {
TIntV& chars = (rnd.GetUniDevInt(100) < percIgnored) ? chIgnored : chNonIgnored;
int j = rnd.GetUniDevInt(chars.Len());
v.Add(chars[j]); }
// Run the tests with this sequence.
TestWbFindNonIgnored(v);
}
}
}

| void TUniChDb::ToCaseFolded | ( | TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| const bool | turkic = false |
||
| ) | const [inline] |
Definition at line 1636 of file unicode.h.
References caseFolding, and TUniCaseFolding::FoldInPlace().
Referenced by TUnicode::ToCaseFolded().
{ caseFolding.FoldInPlace(src, srcIdx, srcCount, turkic); }


| void TUniChDb::ToCaseFolded | ( | TSrcVec & | src, |
| const bool | turkic = false |
||
| ) | const [inline] |
Definition at line 1637 of file unicode.h.
References ToCaseFolded().
Referenced by ToCaseFolded().
{ ToCaseFolded(src, 0, src.Len(), turkic); }


| void TUniChDb::ToSimpleCaseConverted | ( | TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| const TCaseConversion | how | ||
| ) | const |
Definition at line 3066 of file unicode.h.
References ccLower, ccTitle, ccUpper, FindNextWordBoundary(), THash< TKey, TDat, THashFunc >::GetKeyId(), h, IAssert, TUniChInfo::simpleLowerCaseMapping, TUniChInfo::simpleTitleCaseMapping, and TUniChInfo::simpleUpperCaseMapping.
Referenced by ToSimpleLowerCase(), ToSimpleTitleCase(), and ToSimpleUpperCase().
{
bool seenCased = false; size_t nextWordBoundary = srcIdx;
for (const size_t origSrcIdx = srcIdx, srcEnd = srcIdx + srcCount; srcIdx < srcEnd; srcIdx++)
{
const int cp = src[TVecIdx(srcIdx)];
int i = h.GetKeyId(cp); if (i < 0) continue;
const TUniChInfo &ci = h[i];
// With titlecasing, the first cased character of each word must be put into titlecase,
// all others into lowercase. This is what the howHere variable is for.
TUniChDb::TCaseConversion howHere;
if (how != ccTitle) howHere = how;
else {
if (srcIdx == nextWordBoundary) { // A word starts/ends here.
seenCased = false;
size_t next = nextWordBoundary; FindNextWordBoundary(src, origSrcIdx, srcCount, next);
IAssert(next > nextWordBoundary); nextWordBoundary = next; }
bool isCased = IsCased(cp);
if (isCased && ! seenCased) { howHere = ccTitle; seenCased = true; }
else howHere = ccLower;
}
int cpNew = (howHere == ccTitle ? ci.simpleTitleCaseMapping : howHere == ccUpper ? ci.simpleUpperCaseMapping : ci.simpleLowerCaseMapping);
if (cpNew >= 0) src[TVecIdx(srcIdx)] = cpNew;
}
}


| void TUniChDb::ToSimpleLowerCase | ( | TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount | ||
| ) | const [inline] |
Definition at line 1610 of file unicode.h.
References ccLower, and ToSimpleCaseConverted().
Referenced by TUnicode::ToSimpleLowerCase().
{ ToSimpleCaseConverted(src, srcIdx, srcCount, ccLower); }


| void TUniChDb::ToSimpleLowerCase | ( | TSrcVec & | src | ) | const [inline] |
Definition at line 1613 of file unicode.h.
References ToSimpleLowerCase().
Referenced by ToSimpleLowerCase().
{ ToSimpleLowerCase(src, 0, src.Len()); }


| void TUniChDb::ToSimpleTitleCase | ( | TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount | ||
| ) | const [inline] |
Definition at line 1611 of file unicode.h.
References ccTitle, and ToSimpleCaseConverted().
Referenced by TUnicode::ToSimpleTitleCase().
{ ToSimpleCaseConverted(src, srcIdx, srcCount, ccTitle); }


| void TUniChDb::ToSimpleTitleCase | ( | TSrcVec & | src | ) | const [inline] |
Definition at line 1614 of file unicode.h.
References ToSimpleTitleCase().
Referenced by ToSimpleTitleCase().
{ ToSimpleTitleCase(src, 0, src.Len()); }


| void TUniChDb::ToSimpleUpperCase | ( | TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount | ||
| ) | const [inline] |
Definition at line 1609 of file unicode.h.
References ccUpper, and ToSimpleCaseConverted().
Referenced by TUnicode::ToSimpleUpperCase().
{ ToSimpleCaseConverted(src, srcIdx, srcCount, ccUpper); }


| void TUniChDb::ToSimpleUpperCase | ( | TSrcVec & | src | ) | const [inline] |
Definition at line 1612 of file unicode.h.
References ToSimpleUpperCase().
Referenced by ToSimpleUpperCase().
{ ToSimpleUpperCase(src, 0, src.Len()); }


| void TUniChDb::WbFindCurOrNextNonIgnored | ( | const TSrcVec & | src, |
| size_t & | position, | ||
| const size_t | srcEnd | ||
| ) | const [inline, protected] |
Definition at line 1422 of file unicode.h.
References IsWbIgnored().
Referenced by TestWbFindNonIgnored().
{
while (position < srcEnd && IsWbIgnored(src[TVecIdx(position)])) position++; }


| void TUniChDb::WbFindNextNonIgnored | ( | const TSrcVec & | src, |
| size_t & | position, | ||
| const size_t | srcEnd | ||
| ) | const [inline, protected] |
Definition at line 1425 of file unicode.h.
References IsWbIgnored().
Referenced by FindNextSentenceBoundary(), FindNextWordBoundary(), and TestWbFindNonIgnored().
{
if (position >= srcEnd) return;
position++; while (position < srcEnd && IsWbIgnored(src[TVecIdx(position)])) position++; }

| void TUniChDb::WbFindNextNonIgnoredS | ( | const TSrcVec & | src, |
| size_t & | position, | ||
| const size_t | srcEnd | ||
| ) | const [inline, protected] |
Definition at line 1429 of file unicode.h.
References IsWbIgnored().
{
if (position >= srcEnd) return;
if (IsSbSep(src[TVecIdx(position)])) { position++; return; }
position++; while (position < srcEnd && IsWbIgnored(src[TVecIdx(position)])) position++; }

| bool TUniChDb::WbFindPrevNonIgnored | ( | const TSrcVec & | src, |
| const size_t | srcStart, | ||
| size_t & | position | ||
| ) | const [inline, protected] |
Definition at line 1434 of file unicode.h.
References IsWbIgnored().
Referenced by CanSentenceEndHere(), FindNextSentenceBoundary(), FindNextWordBoundary(), and TestWbFindNonIgnored().
{
if (position <= srcStart) return false;
while (position > srcStart) {
position--; if (! IsWbIgnored(src[TVecIdx(position)])) return true; }
return false; }

friend class TUniCaseFolding [friend] |
Definition at line 1268 of file unicode.h.
Referenced by Clr(), GetCaseFolded(), Load(), LoadTxt(), Save(), Test(), and ToCaseFolded().
Definition at line 1266 of file unicode.h.
Referenced by AddDecomposition(), Clr(), Load(), LoadTxt(), LoadTxt_ProcessDecomposition(), and Save().
Definition at line 1263 of file unicode.h.
Referenced by AddDecomposition(), Clr(), GetCaseConverted(), GetCat(), GetCharName(), GetCombiningClass(), GetSbFlags(), GetScript(), GetSimpleCaseConverted(), GetSubCat(), GetWbFlags(), InitDerivedCoreProperties(), InitLineBreaks(), InitPropList(), InitScripts(), InitWordAndSentenceBoundaryFlags(), IsGetChInfo(), IsPrivateUse(), IsSbFlag(), IsSurrogate(), IsWbFlag(), IsWbIgnored(), Load(), LoadTxt(), Save(), TUniChDb::TSubcatHelper::SetCat(), TUniChDb::TSubcatHelper::TestCat(), TestComposition(), TestWbFindNonIgnored(), and ToSimpleCaseConverted().
TUniTrie<TInt> TUniChDb::sbExTrie [protected] |
Definition at line 1461 of file unicode.h.
Referenced by CanSentenceEndHere(), SbEx_Add(), SbEx_Clr(), and SbEx_Set().
Definition at line 1265 of file unicode.h.
Referenced by Clr(), GetScriptByName(), GetScriptName(), InitScripts(), Load(), and Save().
Definition at line 1272 of file unicode.h.
Referenced by GetScript(), InitAfterLoad(), and LoadTxt().
Definition at line 1271 of file unicode.h.
Referenced by Clr(), GetCaseConverted(), InitSpecialCasing(), Load(), and Save().
Definition at line 1271 of file unicode.h.
Referenced by Clr(), GetCaseConverted(), InitSpecialCasing(), Load(), and Save().
Definition at line 1271 of file unicode.h.
Referenced by Clr(), GetCaseConverted(), InitSpecialCasing(), Load(), and Save().
 1.8.0
1.8.0