

Strategies for Pre-training Graph Neural Networks
We develop a strategy for pre-training Graph Neural Networks (GNNs) and systematically study its effectiveness on multiple datasets, GNN architectures, and diverse downstream tasks.
Motivation
Many domains in machine learning have datasets with a large number of related but different tasks. Those domains are challenging because task-specific labels are often scarce and test examples can be distributionally different from examples seen during training. An effective solution to these challenges is to pre-train a model on related tasks where data is abundant, and then fine-tune it on a downstream task of interest. While pre-training has been effective for improving many language and vision domains, pre-training on graph datasets remains an open question.Method
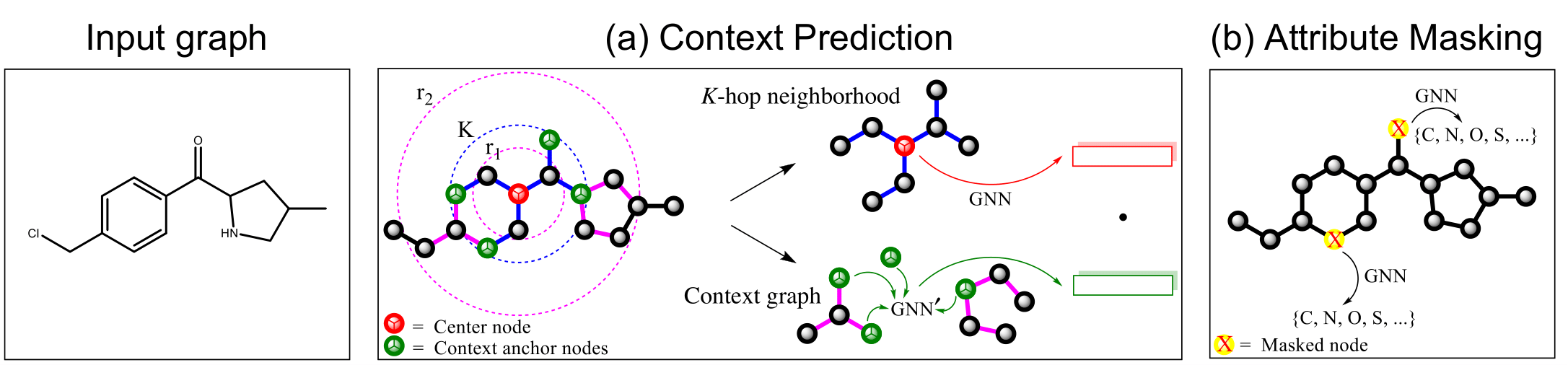
We develop a strategy for pre-training Graph Neural Networks (GNNs). Crucial to the success of our strategy is to pre-train an expressive GNN at the level of individual nodes as well as entire graphs.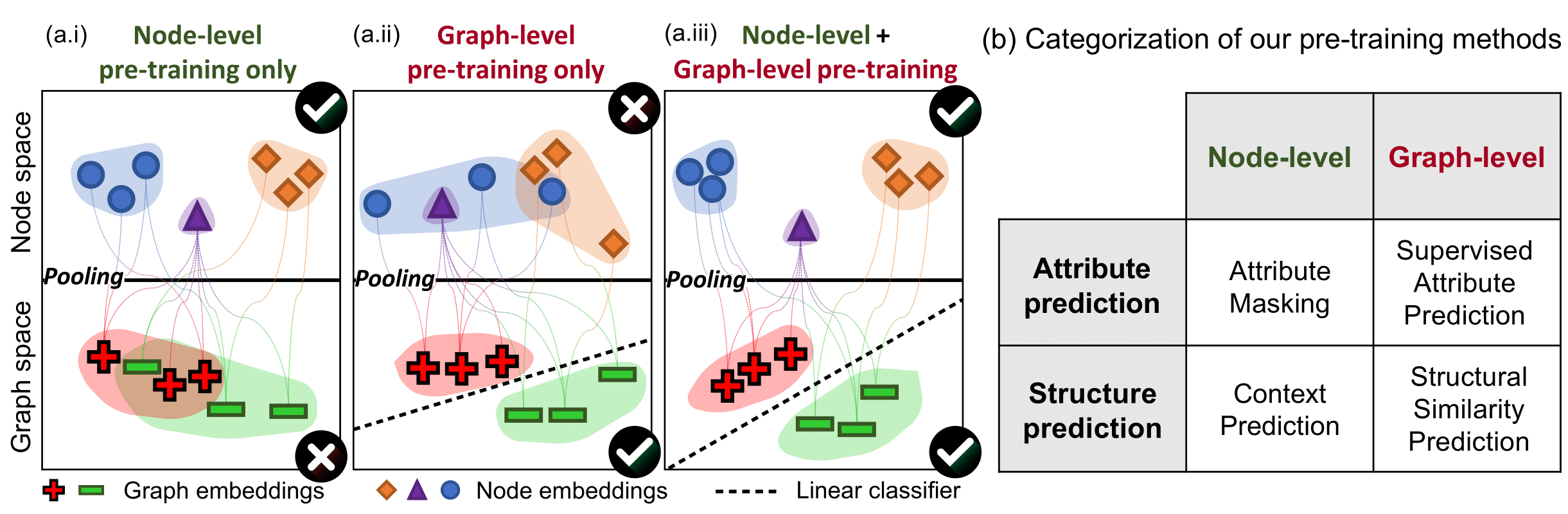
Code
Python code to reproduce our experiments is available on GitHub.Datasets
The datasets used are included in the code repository.Contributors
The following people contributed to this work:Weihua Hu*
Bowen Liu*
Joseph Gomes
Marinka Zitnik
Percy Liang
Vijay Pande
Jure Leskovec