

Learning to Accelerate Partial Differential Equations via Latent Global Evolution
We introduce Latent Evolution of PDEs (LE-PDE), a simple, fast and scalable method to accelerate the simulation and inverse optimization of PDEs. Compared to state-of-the-art deep learning-based surrogate models and other strong baselines, LE-PDE achieves up to 128× reduction in the dimensions to update, and up to 15× improvement in speed, while achieving competitive accuracy.
Method
Simulating the time evolution of Partial Differential Equations (PDEs) of large-scale systems is crucial in many scientific and engineering domains such as fluid dynamics, weather forecasting and their inverse optimization problems. However, both classical solvers and recent deep learning-based surrogate models are typically extremely computationally intensive, because of their local evolution: they need to update the state of each discretized cell at each time step during inference. Here we develop Latent Evolution of PDEs (LE-PDE), a simple, fast and scalable method to accelerate the simulation and inverse optimization of PDEs. LE-PDE learns a compact, global representation of the system and efficiently evolves it fully in the latent space with learned latent evolution models. As shown in the following figure, LE-PDE has two modes: in forward mode (green), it evolves the dynamics in a global latent space via latent evolution model $g$. In inverse optimization mode (red), it optimizes parameter $p$ (e.g. boundary) through backpropagation via latent unrolling. The compressed latent vector and dynamics can significantly speed up both modes.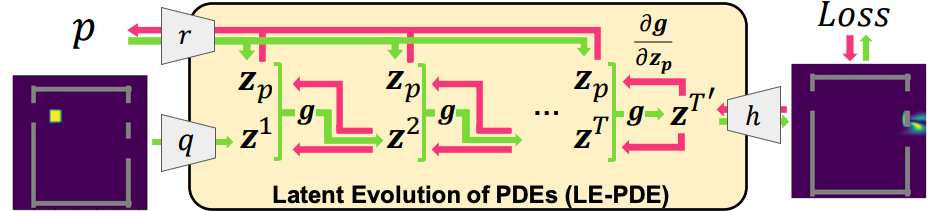
To encourage more accurate long-term rollout, we introduce new learning objectives that combine multi-step loss in input space $L_\text{multi-step}$, latent consistency loss $L_\text{consistency}$ and reconstruction loss $L_\text{recons}$, trained end-to-end to effectively learn such latent dynamics to ensure long-term stability. We further introduce techniques for speeding-up inverse optimization of boundary conditions for PDEs via backpropagation through time in latent space, and an annealing technique to address the non-differentiability and sparse interaction of boundary conditions. We test our method in a 1D benchmark of nonlinear PDEs, 2D Navier-Stokes flows into turbulent phase and an inverse optimization of boundary conditions in 2D Navier-Stokes flow. Compared to state-of-the-art deep learning-based surrogate models and other strong baselines, we demonstrate up to 128x reduction in the dimensions to update, and up to 15x improvement in speed, while achieving competitive accuracy.
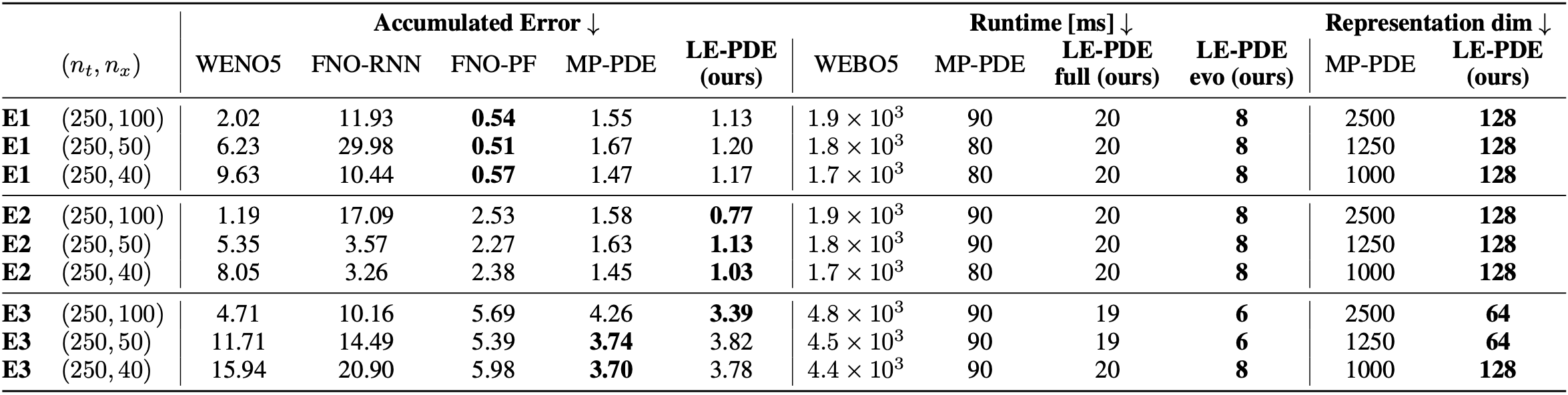
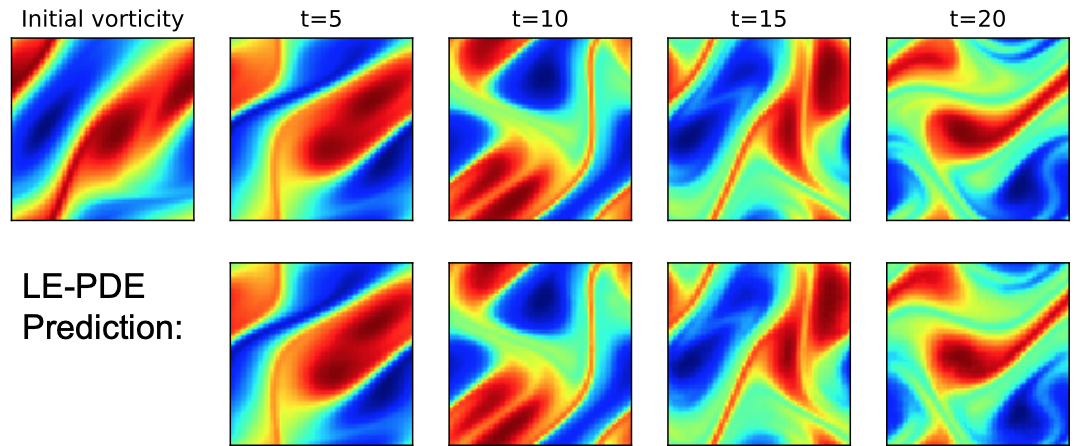
For example, the above table shows performance of models in 1D family of nonlinear PDEs, for scenarios E1, E2 and E3. E2 and E3 test generalization to PDEs with novel coefficients in the same family. We see that compared to state-of-the-art models (MP-PDE), in 1D experiment LE-PDE achieves up to 39x reduction in representation dimension, 15x speed-up while achieving competitive accuracy. For another example, the following figure shows a visualization of 2D Navier-Stokes equation.
In the inverse optimization of the boundary, LE-PDE achieves both faster and more accurate optimization compared to ablation of without latent evolution, and state-of-the-art Fourier Neural Operator (FNO):

For more detailed methods and results, please see the paper.
It is also included in a talk given at the DDPS seminar at Lawrence Livermore National Laboratory (37min-45min).
Code
A reference implementation of LE-PDE in PyTorch will be available on GitHub.Datasets
The datasets used by LE-PDE are included and can be generated in the code repository.Contributors
The following people contributed to LE-PDE:Tailin Wu
Takashi Maruyama
Jure Leskovec