

Open-World Semi-Supervised Learning
ORCA simultaneously recognizes classes previously seen in the labeled dataset and discovers novel, never-before-seen classes in a new open-world semi-supervised learning setting.
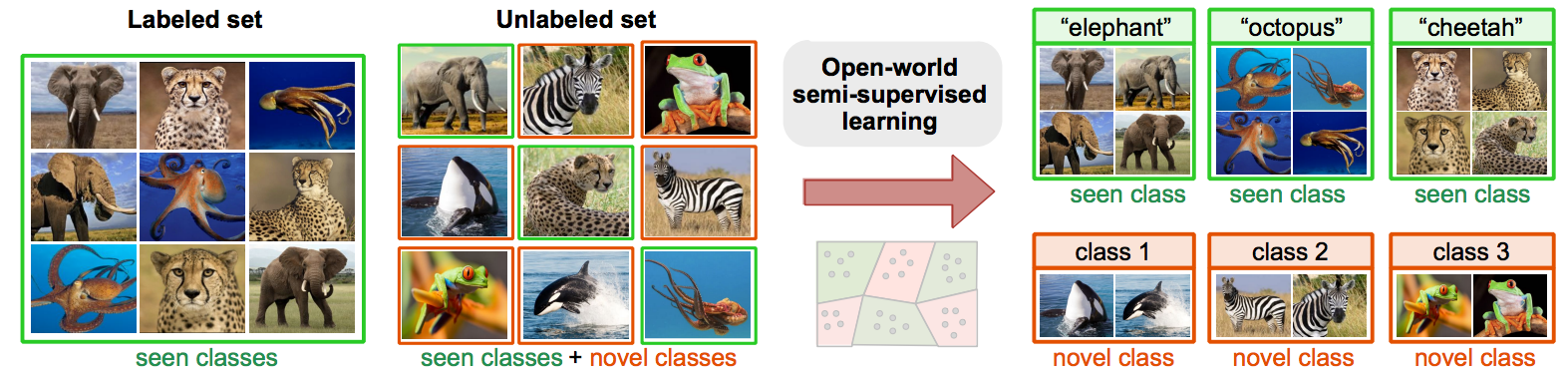
The vast majority of machine learning models are designed for the closed-world setting rooted in the assumption that training and test data come from the same set of predefined classes. However, this assumption rarely holds in practice, as labeling data depends on the domain-specific knowledge which can be incomplete and insufficient to account for all possible scenarios. In contrast, the real world is inherently dynamic and open — new classes can emerge in the test data that have never been encountered during training.
We introduce open-world semi-supervised learning setting. Under this setting, we are given a labeled training dataset as well as an unlabeled dataset. The labeled dataset contains instances that belong to a set of seen classes, while instances in the unlabeled/test dataset belong to both the seen classes as well as to an unknown number of unseen classes. The model then needs to either classify instances into one of the previously seen classes, or discover new classes and assign instances to them.
Publication
Open-World Semi-Supervised Learning.
Kaidi Cao*, Maria Brbić*, Jure Leskovec.
International Conference on Learning Representations (ICLR), 2022.
Our approach: ORCA
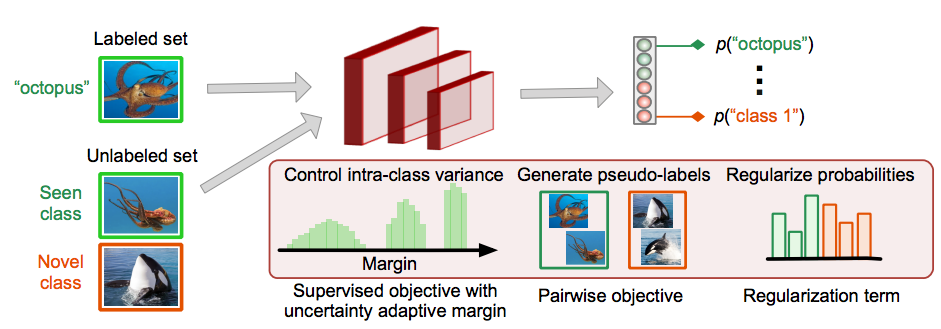
To address the challenges of open-world SSL, we propose ORCA, an approach that effectively assigns examples from the unlabeled data to either previously seen classes, or forms novel classes by grouping similar instances. ORCA is an end-to-end deep learning framework, where the key to our approach is a novel uncertainty adaptive
margin mechanism that gradually decreases plasticity and increases discriminability of the model
during training. This mechanism effectively reduces an undesired gap between intra-class variance of
seen with respect to the novel classes caused by learning seen classes faster than the novel, which
we show is a critical difficulty in this setting.
Results
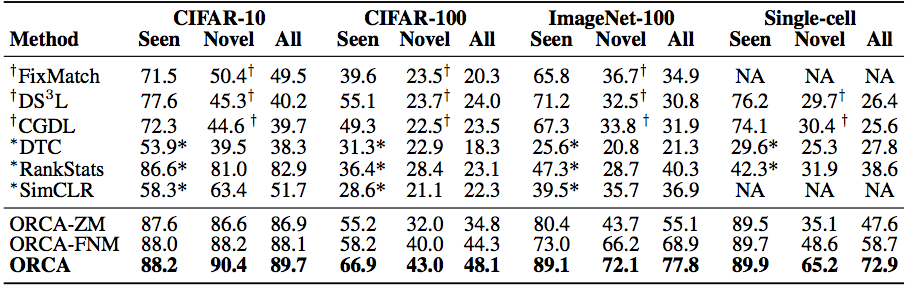
We evaluate ORCA on three benchmark image classification datasets adapted for open-world SSL setting and a single-cell annotation dataset from biology domain. Since no existing methods can operate
under the open-world SSL setting we extend existing state-of-the-art SSL, open-set recognition and
novel class discovery methods to the open-world SSL and compare them to ORCA. Experimental
results demonstrate that ORCA effectively addresses the challenges of open-world SSL setting and
consistently outperforms all baselines by a large margin. Specifically, ORCA achieves 25% and
96% improvements on seen and novel classes of the ImageNet dataset. Moreover, we show that
ORCA is robust to unknown number of novel classes, different distributions of seen and novel classes,
unbalanced data distributions, pretraining strategies and a small number of labeled examples.
Code
A PyTorch implementation of ORCA is available on GitHub.
Datasets
We use standard benchmark image classification datasets:CIFAR-10
CIFAR-100
ImageNet
and Tabula Muris single-cell annotation dataset:
Contributors
The following people contributed to this work:Kaidi Cao*
Maria Brbić*
Jure Leskovec